时间:2026-01-28 18:02
人气:
作者:admin
如果你观察过一段时间行业里的大模型微调项目,会发现一个很有意思的现象。
PPO 的讨论热度一直很高,但真正长期稳定跑 PPO 的团队并不多。
更多时候,你会听到的是:
于是 PPO 很容易被贴上一个标签:
“理论上很强,工程上很坑。”
但这个结论,其实并不公平。
因为在真实业务里,PPO 从来就不是一个“通用增强方案”,
而是一个非常有指向性的工具。
PPO 不是让模型更聪明的,
它是用来改变模型“选择什么行为”的。
一旦你从这个角度去看 PPO,它的应用边界会变得非常清晰。
这是理解 PPO 应用的第一道分水岭。
在大模型能力层面,我们可以粗暴地分两类问题:
第一类问题,用 PPO 基本是浪费时间。
第二类问题,PPO 才真正有价值。
比如:
这些问题,本质上都不是“能力不足”,
而是行为偏好没对齐。
这是 PPO 在工业界最成熟、最稳定的一类应用。
你会发现,在很多真实系统里,问题并不是模型不知道“什么是违规”,
而是:
用 SFT 去解决这类问题,通常会遇到两个瓶颈:
而 PPO 在这里的优势在于:
你不需要告诉模型“正确答案是什么”,
你只需要告诉它“这样好,那样不好”。
以安全拒答为例:
你很难为这种问题写出“标准答案”,
但人类很容易在多个输出中选出“更好的那个”。
这正是 PPO 擅长的地方。

安全拒答多候选行为对比示意图
很多团队一开始会尝试:
短期内,确实有效。
但随着业务复杂度上升,你会发现:
这是因为:
你在用“确定性工具”解决“偏好问题”。
而 PPO,本质上是一个“偏好压缩器”,
它能把大量人类判断,压缩成模型的选择倾向。
这是很多人低估 PPO 价值的一类场景。
很多团队会觉得:
“风格问题,用 prompt 就好了。”
在 demo 阶段,这句话通常是对的。
但在长期运行的系统里,你很快会发现:
而且,更关键的是:
prompt 只影响“表达”,不影响“决策倾向”。
同样是回答一个模糊问题:
如果你的业务希望它稳定地偏向某一种行为,
那 PPO 往往比 prompt 更可靠。
因为 PPO 调的是:
在多种可能回答中,
哪一种更值得被选择。
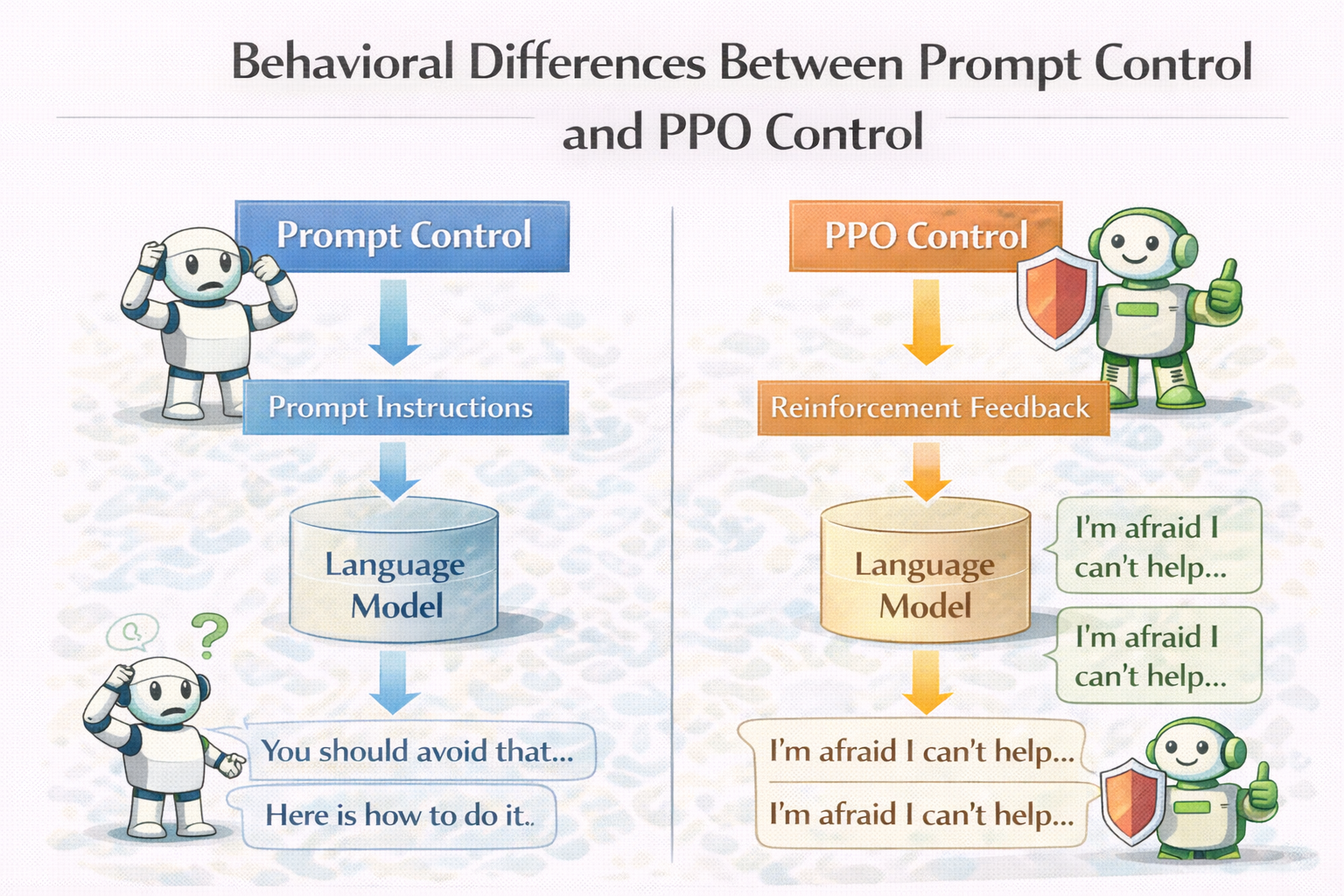
prompt 控制 vs PPO 控制行为差异图
在真实业务中,很多系统都有隐含人格:
这些人格,很难通过规则或 SFT 精确描述,
但人类在比较输出时,却非常容易达成一致。
PPO 的优势就在于:
它直接学习这种“比较偏好”。
这是一个不常被公开讨论,但非常真实的应用场景。
在一些系统里,模型并不是直接给最终答案,而是:
这些输出一旦“过于自信”,就会带来风险。
典型例子包括:
在这些场景中,你真正希望的是:
模型在“不确定时”,
更倾向于保守、提示风险、建议人工介入。
而这类“保守倾向”,几乎不可能通过 SFT 学出来。
因为你无法为每一个“不确定场景”写出明确标签。
PPO 在这里的作用是:
这是 PPO 项目失败率高的一个重要原因。
如果你的目标是:
那 PPO 很可能会让你失望。
因为 PPO 的优化目标,从来就不是“正确性”,
而是偏好一致性。
这也是为什么,很多人 PPO 跑完之后会说:
“模型好像没变聪明,反而更保守了。”
这不是失败,
而是 PPO 正常工作的结果。
在真实项目中,我非常建议用下面这个判断法:
问自己一个问题:
如果我给模型 3 个不同回答,人类能不能稳定地选出一个“更好的”?
这个问题,比任何算法讨论都更重要。
# 生成多个候选
responses = policy.generate(prompt, n=4)
# 人类或 reward model 做偏好判断
preferred = select_best(responses)
# PPO 学的不是“答案”,而是“偏好”
reward = compare(preferred, responses)
注意:
这里没有“标准答案”。
PPO 学的是:
在类似情况下,
哪种行为更值得重复。
说实话,PPO 并不便宜。
它至少要求:
如果你的团队:
那 PPO 很可能是过早引入复杂度。
这点必须说清楚。
PPO 在以下情况下,极容易出问题:
这时 PPO 不会“修正问题”,
而是把问题固化进模型行为里。
在评估某个业务场景是否真的适合上 PPO 时,用LLaMA-Factory online先跑一轮小规模 PPO 实验、对比模型在固定评估集上的行为变化,是一个非常低成本的方式。它可以帮你在“值得投入”和“及时止损”之间,更早做出判断。
如果要用一句话总结 PPO 的应用价值,那应该是:
PPO 不是解决“模型不行”的工具,
而是解决“模型老是选错”的工具。
当你真正站在这个角度看 PPO,你会发现:
真正成熟的团队,不是“敢不敢用 PPO”,
而是知道什么时候该用,什么时候坚决不用。

 关注微信
关注微信