时间:2026-01-21 18:46
人气:
作者:admin
说句实话,我第一次接触向量数据库的时候,根本没想过要自己搭一套。
原因也很现实:
所以一开始我的想法非常简单:
我只需要一个“能做语义检索的东西”,
至于它内部怎么跑的,说实话并不关心。
直到后来在项目里遇到几个非常具体的问题:
那时候我才意识到一个问题:
如果你完全不了解向量数据库是怎么“拼”起来的,
那你其实很难用好它。
这篇文章,就是在这种背景下写的。
不是为了造一个“能对外卖钱的数据库”,而是为了搞清楚:
一套最小可用的向量数据库,从工程角度到底需要哪些东西?
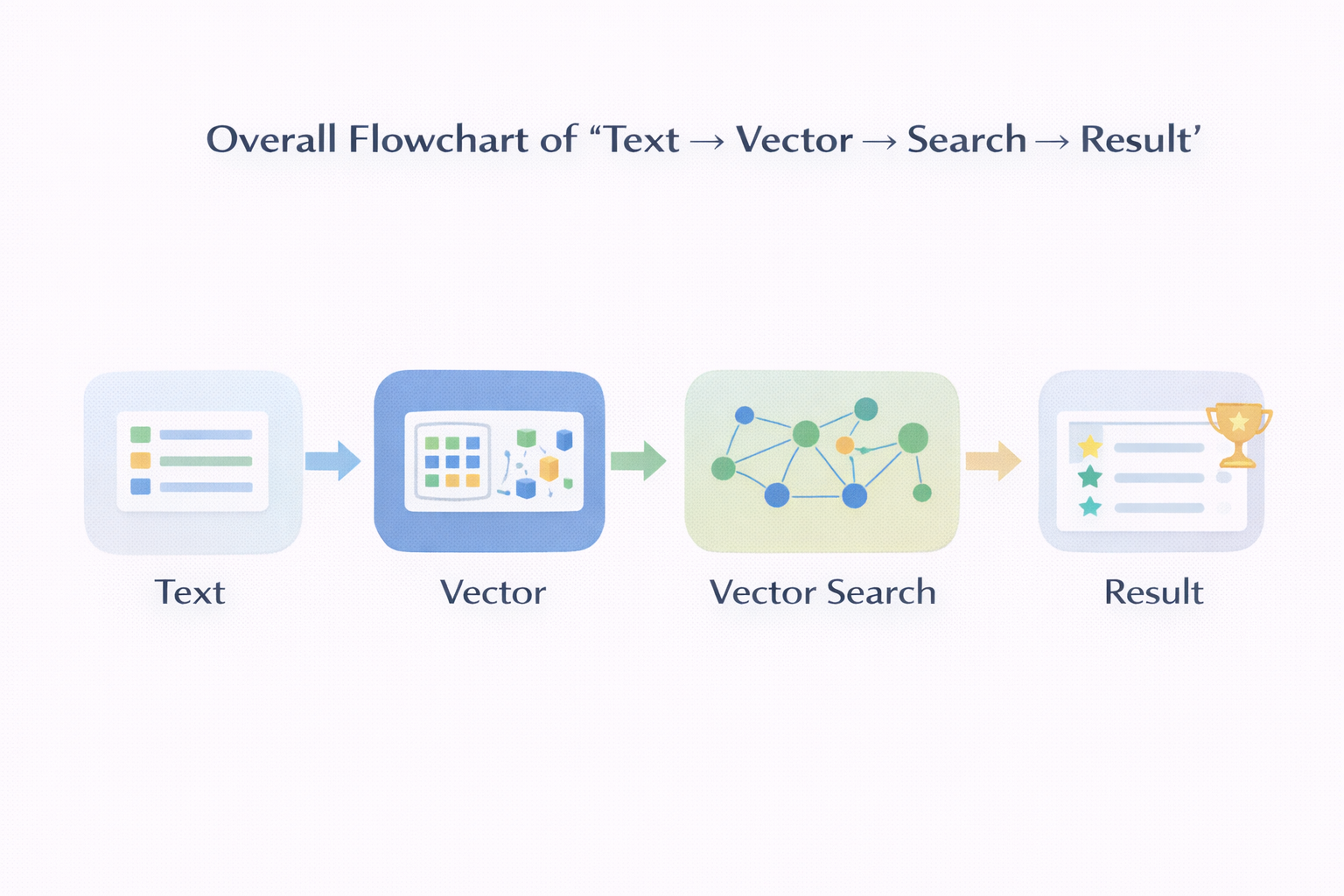
在开始写代码之前,我建议先把目标说清楚。
这篇文章里,我们要做的事情其实很克制:
换句话说,我们要实现的是:
一个最小但完整的文本语义检索系统
它不追求极限性能,但每一层都是真实向量数据库会有的结构。
所有向量数据库的起点,其实都非常一致:
你得先有向量。
这一步通常叫 embedding。
一开始我也犯过一个很常见的错误:
embedding 模型,越大越好吧?
后来发现,完全不是这么回事。
在真实工程里,你要考虑的其实是:
对“文本语义检索”这个任务来说,一个稳定、维度适中、输出一致的模型,往往比一个“看起来更强”的模型更重要。
如果你是第一次搭:
因为后面你会发现,问题往往不出在 embedding 上。
当你已经能把文本变成向量,接下来一个非常自然的问题就来了:
向量该怎么存?
很多人第一反应是:
直接存成 list / numpy array 不就行了?
在数据量很小的时候,这个想法完全没问题。
但一旦你认真算一下空间和性能,就会开始犹豫。
假设:
那你光原始向量就已经是几十 GB。
这时候你就会意识到:
“原样存”这条路,迟早会走不下去。
我当时的第一反应其实是抗拒的:
我只是想做个语义检索,
怎么突然就要研究压缩了?
但后来你会发现,压缩在向量数据库里承担的角色非常特殊:
哪怕你第一版系统里不真的做复杂压缩,
你也要在结构上给它留位置。
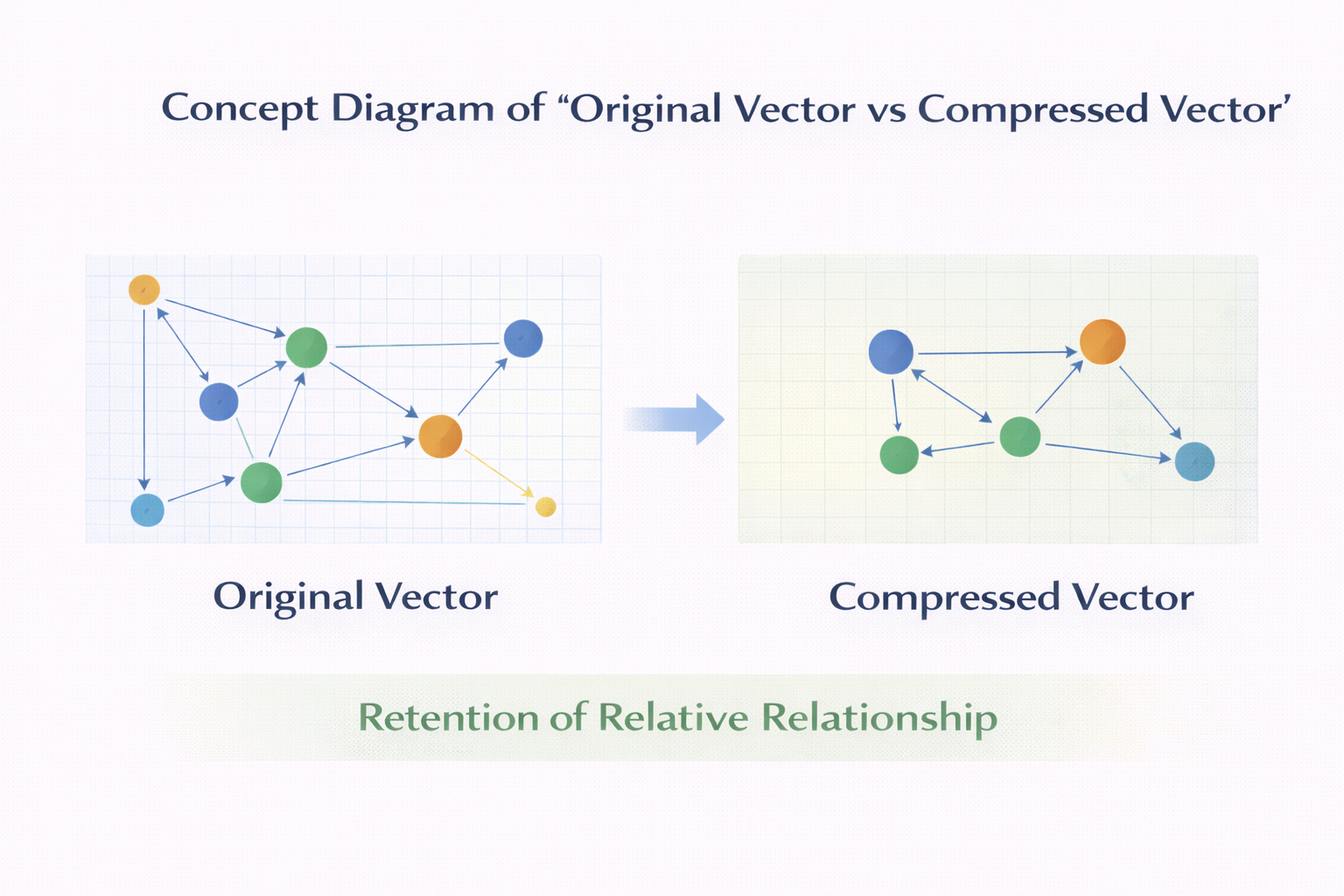
原始向量 vs 压缩向量 概念图
在正式引入索引之前,我强烈建议你先实现一版最朴素的检索。
也就是:
因为这是你理解后面一切优化的“对照组”。
在数据量小时,你会觉得:
好像也没那么慢?
但只要你把数据量放大一个数量级,
延迟和资源占用就会立刻告诉你现实有多残酷。
这一步非常重要,因为它会让你发自内心地接受:
必须引入近似搜索。
我第一次认真看 ANN 相关资料的时候,内心其实是有点抗拒的。
因为这意味着一个非常不工程师直觉的事实:
我主动放弃“最优解”。
但后来你会发现,这不是退步,而是妥协。
在语义检索里:
所以 ANN 的存在,本质上是:
把“精确性”换成“可用性”。
这是很多人会卡住的地方。
我的建议非常直接:
第一版,千万别自己实现复杂索引算法。
不是因为你写不出来,而是因为:
更好的方式是:
你要清楚的是:
向量数据库真正的难点,不是“有没有索引”,
而是索引和系统其他部分怎么配合。
当你把系统各个模块拼起来,一次语义检索请求,通常会经历:
一个很重要的工程细节是:
真正参与精确相似度计算的向量,数量应该很少。
如果不是这样,那你的系统迟早会顶不住。

向量检索完整请求路径图
很多“从零搭建”的教程,都会下意识忽略 metadata。
但在真实系统里,没有 metadata 的向量数据库几乎没法用。
比如:
工程上的现实是:
向量检索只是第一步,
真正能不能用,取决于你怎么把它和结构化条件结合。
很多人会下意识把性能问题归结为:
但我在实践中遇到的瓶颈,更多来自:
这也是为什么你会发现:
同样的算法,不同实现,性能差距巨大。
如果你真的按这条路从零搭一遍,你会明显感觉到:
这也是为什么,大多数团队最终都会选择:
我现在对“自己搭向量数据库”的看法是这样的:
你不一定要永远自己维护一套,
但你最好至少亲手搭过一次。
在真实项目中,你往往不仅要处理向量检索,还要同时面对:
如果你把所有东西都从零写一遍,成本会非常高。
这也是为什么我后来会在一些项目里,先借助像 LLaMA-Factory online 这样的工具,把模型微调、数据处理、实验流程这些容易反复踩坑的部分先跑顺,再把精力放在真正需要定制的系统设计上。
它解决的不是“算法多高级”,而是一个很现实的问题:
让工程师少在重复的工程细节里消耗精力。

 关注微信
关注微信