时间:2026-01-28 12:23
人气:
作者:admin
如果你问一个已经上线向量数据库的团队:
“你们的向量检索效果怎么样?”
得到的回答往往是:
这类系统,通常不是完全不能用,
但也很少让人真正放心。
原因并不在于向量数据库“不成熟”,
而在于:从建库到稳定可用,中间有一整段工程空白,被严重低估了。
很多教程,会把“向量数据库实战”理解成:
但在真实项目里,这三步只是:
“系统刚刚有可能开始工作”
真正决定成败的,是后面这些问题:
这是几乎所有实战翻车的起点。
很多人选向量数据库的理由是:
“RAG 不是都要用吗?”
但在工程上,这是一个非常危险的动机。
在真正选型前,你至少要回答清楚三件事:
不同答案,对向量数据库的要求,完全不同。
这是一个非常容易被忽略的事实。
在向量数据库实战中,embedding 模型几乎定义了你整个系统的“世界观”。
因为一旦 embedding 选定:
这些判断,就已经被固化进向量空间了。
如果 embedding 本身就不适合你的领域,
那后面所有检索优化,基本都是在“补救”。

不同 embedding 模型导致的相似性差异示意图
很多团队在系统上线一段时间后,会尝试升级 embedding。
然后你会看到:
这是因为:
向量数据库不是“无状态组件”,
它的行为强烈依赖 embedding 的语义空间。
所以在实战中,embedding 版本管理,是必须被认真对待的。
这一点前面那篇《RAG 文档切分》已经讲过很多,但在实战里,还是值得再强调一次。
在向量数据库里:
而 chunk 的质量,直接决定:
如果你在建库时,随意切分、一次性切完所有文档,
那后面你几乎一定会后悔。
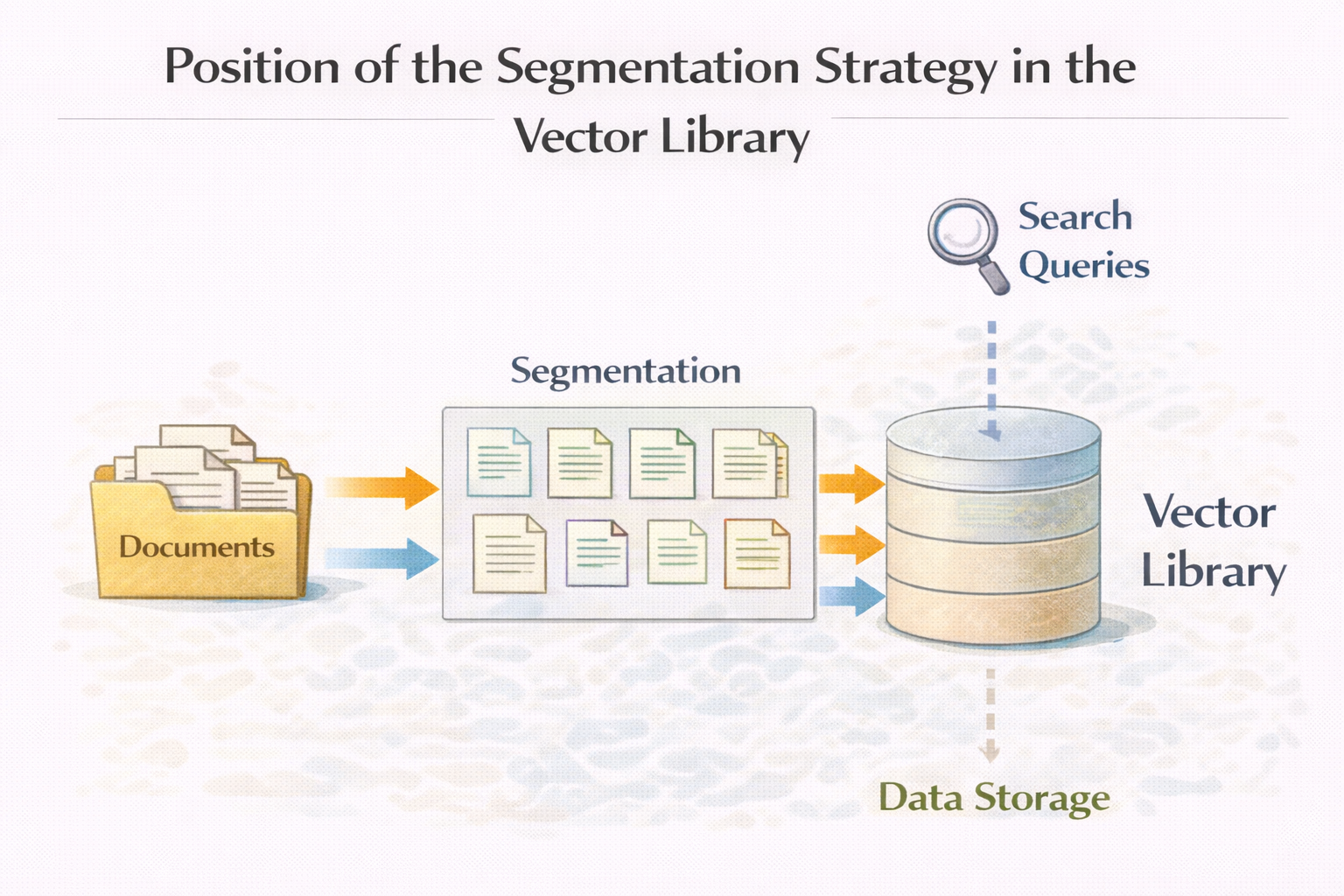
切分策略在向量库中的位置示意图
很多人第一次看到:
vector_db.insert(embeddings)
不报错,
查询能返回结果,
就会产生一种错觉:
“向量数据库这块,应该没问题了。”
但从工程经验来看,这只是:
第一天不报错而已
真正的问题,往往在:
在向量数据库实战中,你几乎一定会遇到这个阶段。
初期:
后期:
这不是数据库退化了,
而是数据分布变了,而你的策略没变。
这是向量数据库实战中最头疼、但无法回避的问题。
你会看到很多这样的结果:
在这一刻,你会意识到:
向量数据库只负责“找像的”,
不负责“找对的”。
这也是为什么,单纯的向量检索,在真实系统里,几乎一定不够。
在很多真实项目中,向量数据库效果的质变,发生在引入 rerank 的那一刻。
向量检索解决的是:
Rerank 解决的是:
如果你只用向量数据库,不做 rerank,
那系统迟早会被噪声淹没。
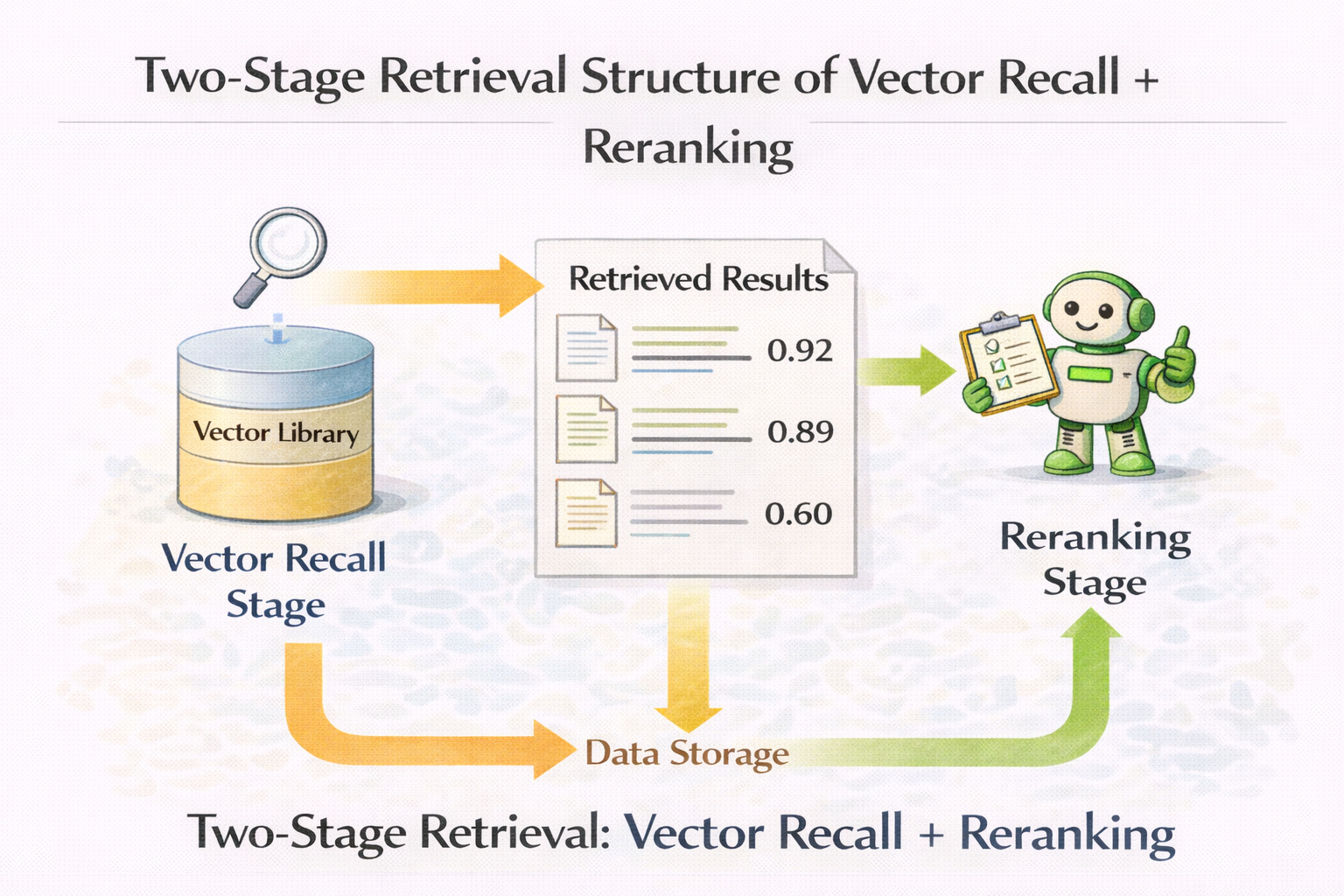
向量召回 + rerank 的两阶段检索结构图
candidates = vector_db.search(query, top_k=20)
reranked = rerank_model.rank(query, candidates)
final = reranked[:3]
这段代码看起来很简单,
但它背后表达的是一个非常重要的工程认知:
向量数据库适合做“第一轮筛选”,
而不是最终裁决。
这是很多团队在实战中才意识到的事。
当用户反馈:
“这个问题答错了。”
你必须能回答:
如果你回答不上来,
那系统就不可维护。
在实战中,我非常推荐下面这个顺序:
这个顺序,能帮你避免 80% 的误判。
这是很多团队在后期最痛的地方。
向量数据库一旦成为系统依赖,你就必须考虑:
这时候你会发现:
向量数据库,已经不是一个“组件”,
而是系统的一部分。
很多团队在评估向量数据库效果时,只看最终答案。
但在实战中,更合理的评估应该拆成:
如果第一步就失败了,
后面讨论模型没有意义。
这是一个很重要、但很多人不愿面对的问题。
如果你发现:
那向量数据库,很可能已经变成负资产。
在真实工程中,一个更稳妥的路径往往是:
而不是一开始就:
在向量数据库实战的早期阶段,如果你还在反复验证“向量检索到底是不是适合当前业务”,用LLaMA-Factory online先快速搭一套 RAG + 向量检索原型、对比不同 embedding 和切分策略下的真实输出效果,会比直接投入完整向量库工程更容易看清问题本质,也更容易止损。
如果要用一句话总结向量数据库实战,那应该是:
向量数据库不是“装上就行”的基础设施,
而是一个会深度影响系统行为的核心组件。
真正成熟的实战,不是问:
而是问:
当你能清楚地回答这个问题时,
向量数据库,才会成为资产,而不是拖累。

 关注微信
关注微信