时间:2025-11-29 10:15
人气:
作者:admin

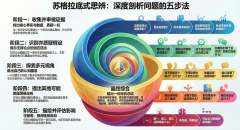
结合IT管理场景,对这五个阶段进行深度解读与应用思考:
核心定义: 找出核心事实与数据,质疑一切。建立坚实的事实基础。
图片关键点: “这条信息从哪里来的?”、“样本量真实吗?”、“数据相关性?”
IT管理者应用与思考:
拒绝“我觉得”: 在处理系统故障或性能问题时,下属常说“我觉得是数据库慢了”。管理者需反问:“Log在哪里?APM监控数据怎么说?复现路径是什么?”
需求伪真伪: 当业务方提出“紧急且必须”的功能时,应用此思维:“这个需求的数据支撑是什么?多少用户反馈了此问题?是核心痛点还是伪需求?”
技术选型陷阱: 看到新技术宣称“性能提升10倍”时,质疑:“测试环境是什么?是否针对特定场景?是否有各方利益相关(如厂商软文)?”
核心定义: 揭示支撑论点的潜在信念。任何论点都建立在未言明的假设之上。
图片关键点: “我们默认哪些是事实?”、“如果我想错了会怎样?”、“我自己有哪些隐蔽偏见?”
IT管理者应用与思考:
挑战隐性假设: 在架构设计时,团队往往假设“流量会线性增长”或“第三方服务永远稳定”。管理者需问:“如果网络断了怎么办?如果流量突增10倍怎么办?”
打破“经验主义”: “我们以前都是这么做的”是最危险的假设。技术环境在变,过去的最佳实践可能是现在的技术债。
识别偏见: 团队是否因为熟悉Java就强行在不适合的场景(如AI训练)使用Java?这是“工具锤子”偏见。
核心定义: 跳出自己的认知图层。引入外部视角,获得全面理解。
图片关键点: “谁不同意这个观点?”、“不同背景的人会怎么看?”、“我们遗漏了谁的声音?”
IT管理者应用与思考:
跨部门视角(Stakeholder Management): 技术不仅仅是代码。
运维视角: “代码写得好,但好部署、好监控吗?”
安全视角: “功能很炫,但数据传输加密了吗?”
业务视角: “架构很完美,但能赶上双十一吗?”
新老员工视角: 听取新员工的意见,他们往往能发现老员工习以为常的“不合理流程”。
客户视角: 作为技术人员,很容易陷入“技术自嗨”。必须强制团队站在最终用户的角度看问题。
核心定义: 跳脱思维定势。在充分理解问题后,进行创造性思考。
图片关键点: “有没有别的切入角度?”、“当前方案的反面是什么?”、“能否整合不同思路?”
IT管理者应用与思考:
方案B与方案C: 在技术评审(Design Review)中,永远不要接受唯一的解决方案。管理者应要求:“如果不使用微服务,单体能不能解决?如果不用自研,买SaaS行不行?”
逆向思维: 面对“系统太慢”的问题,常规思路是优化代码。逆向思路可能是:“是否可以通过业务流程调整,让用户感觉不到慢(如异步处理)?”
整合创新: 能否将开源方案与内部定制相结合,而不是非此即彼?
核心定义: 往前看,预测连锁反应。系统性地预测和评估后果。
图片关键点: “第一、二、三层影响是什么?”、“谁受益,谁受损?”、“可能会引发哪些新问题?”
IT管理者应用与思考:
二阶效应(Second-Order Effects):
决策: 为了赶进度,允许代码不写单元测试。
一阶影响: 上线快了。
二阶影响: Bug增多。
三阶影响: 团队陷入无尽的修Bug循环,新功能开发停滞,士气低落。
技术债评估: 现在的临时方案(Workaround)在未来6个月会变成什么样的阻碍?
团队影响: 引入这个复杂的框架,团队的学习成本是多少?如果核心维护者离职,谁能接手?
复盘原则: 对事不对人(Blameless),不仅关注“发生了什么”,更关注“我们是如何思考的”。
故障 ID / 名称:
发生时间(起止):
影响时长:
严重等级 (P0-P3):
复盘主持人:
苏格拉底式追问: 我们依据的数据来源可靠吗?日志和监控是否完全吻合?
请精确到分钟,列出系统表现、报警时间、人工介入点。
[hh:mm] 现象...
[hh:mm] 报警...
[hh:mm] 操作...
核心报错信息 (Log/Trace):
关键指标变化 (Metrics):
证据质疑: 有没有哪条日志具有误导性?有没有哪个报警被我们忽略了?我们是否基于推测而非数据做出了初步判断?
苏格拉底式追问: 我们之前默认了什么“事实”,结果被证明是错的?
不要只写代码bug,要挖掘背后的思维定势。
直接原因: (例如:空指针异常)
Why 1: 为什么会出现空指针?
Why 2: 为什么测试没覆盖到?
Why 3: (核心)我们潜意识里做了什么假设?
示例:我们假设了第三方API永远会返回标准JSON格式,没有做容错。
示例:我们假设流量增长是线性的,没预料到促销带来的突发脉冲。
我们在哪个环节(设计/开发/测试/发布)过于自信了?
苏格拉底式追问: 跳出技术视角,其他人怎么看这次故障?
用户视角: 用户看到了什么?(白屏?报错?数据错误?)用户的信任度受损了吗?
业务视角: 造成了多少资金/订单损失?是否影响了正在进行的营销活动?
客服/运营视角: 他们是否拥有足够的信息去安抚用户?还是他们也是最后知道的?
开发/运维视角: 报警是否及时?排查工具是否顺手?当时是否压力过大导致判断失误?
苏格拉底式追问: 除了修好Bug,我们还有没有更聪明的路?我们是否只是运气好?
如果故障发生在半夜/流量高峰,后果会严重多少?
我们是因为监控发现的,还是用户投诉才发现的?
侦测层面: 有没有可能在故障发生前5分钟就预警?我们需要什么样的监控指标?
止损层面: 除了回滚,有没有降级开关?如果没有,为什么当初设计时没加?
架构层面: 如果不修这行代码,从架构上能否规避此类问题(例如:熔断、隔离)?
苏格拉底式追问: 修复方案会带来新问题吗?谁负责落实?
类型 | 具 体 措 施 | 负责人 | 截止日期 | 关联Ticket |
修复 | 修复当前Bug | ... | ... | ... |
防御 | 增加单元测试/集成测试 | ... | ... | ... |
监控 | 新增/优化报警规则 | ... | ... | ... |
流程 | 修改Code Review规范 | ... | ... | ... |
为了修复这个Bug,我们引入的新代码是否增加了系统复杂度?
新增的报警规则会不会导致“报警风暴”从而掩盖真正的故障?
这次复盘的结论是否需要同步给其他团队(避免他们踩同样的坑)?
本次故障给我们最大的认知升级是什么?(用一句话总结)
这张图对于技术管理者最大的价值在于,它提供了一套从“解决Bug”升级到“解决系统性问题”的方法论。
初级管理者通常停留在阶段一(看Log)和阶段四(给方案)。
高级管理者则会在阶段二(质疑架构假设)、阶段三(平衡业务/技术/成本)和阶段五(预判长期风险)投入更多精力。
如有想了解更多软件设计与架构, 系统IT,企业信息化, 团队管理 资讯,请关注我的微信订阅号:

作者:Petter Liu
出处:http://www.cnblogs.com/wintersun/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
该文章也同时发布在我的独立博客中-Petter Liu Blog。



 关注微信
关注微信