时间:2026-02-12 22:30
人气:
作者:admin
首先论文中指明了当前Agent memory领域主要有什么研究方向,从下图可以看出,这个领域中研究方向很多,我们逐一拆解
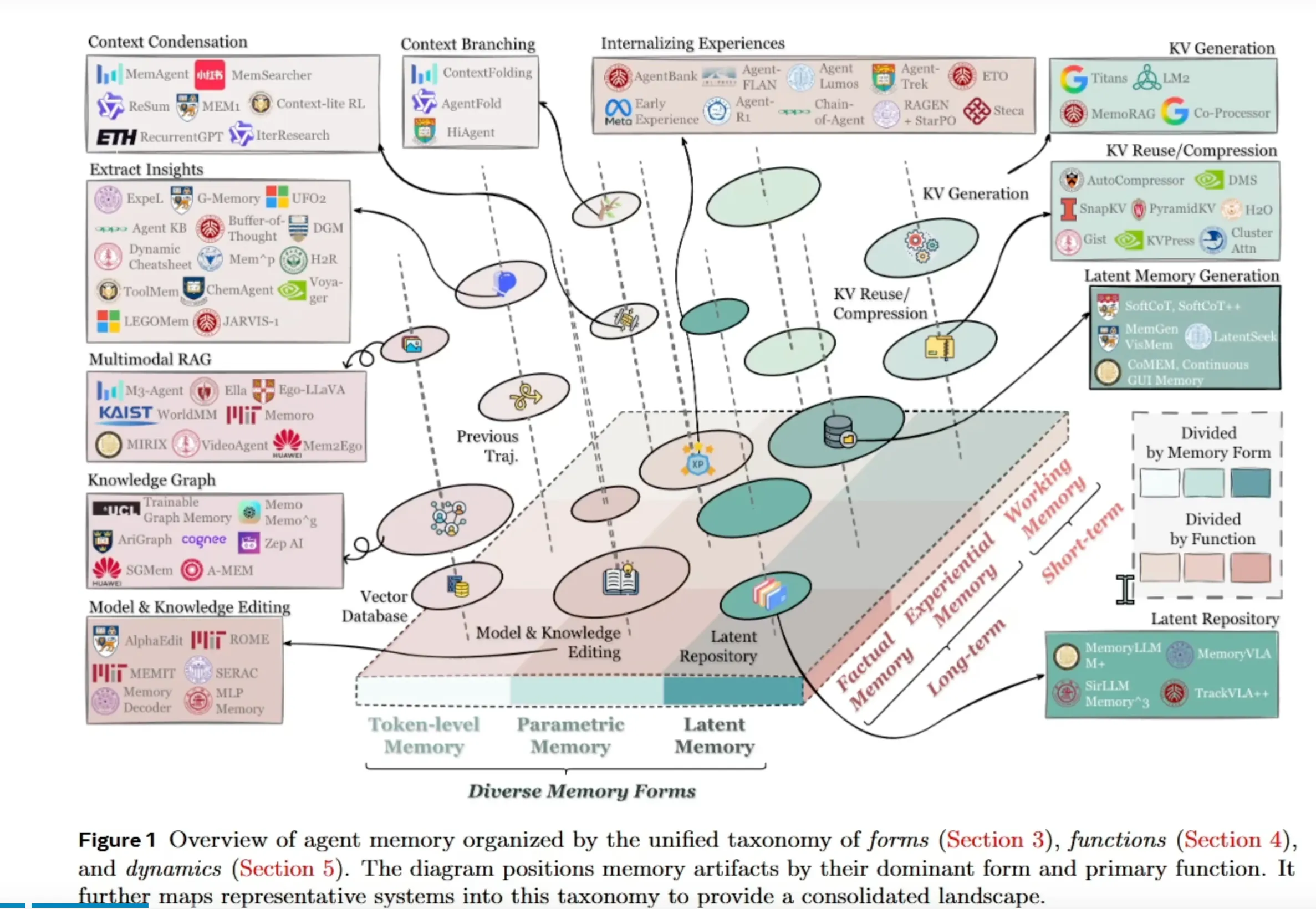
一、 图的核心目的与价值
标题已点明核心:这是一张基于统一分类法绘制的智能体记忆概览图,该分类法包含:
图的价值在于:它将数十个看似独立的AI智能体系统和记忆模块(如 G-Memory , Buffer-of-Thought , JARVIS-1 等)整合到一个统一的框架中,让研究者一眼就能看出某个系统“用哪种形式的记忆,主要解决什么问题”。
| --- | --- |
| 令牌级/明文记忆 | 原始文本或令牌序列,未经深度编码。 | Context Condensation , REsum , Gist |
| 参数记忆 | 知识被编码在神经网络模型的权重参数中。 | Model & Knowledge Editing (如 ROME , SERAC ) |
| 潜在记忆 | 信息被编码在低维稠密向量(嵌入)或隐状态中。 | Vector Database , Latent Repository , AutoCompressor |
| 体验记忆 | 对事件、交互序列的连贯记录,常具时空上下文。 | Experience , Memoro , Mem2Ego , Ego-LLaVA |
| 工作记忆 | 当前任务相关的、被激活的短期信息。 | Working Memory , Short-term , Redis |
| 长期记忆 | 持久化存储的海量知识库。 | Long-term , Agent KB , Knowledge Graph |
| 加密记忆 | 基于区块链或分布式账本,实现不可篡改、可验证的记忆。 | Distributed ledger , Blockchain , Token-level Cryptographic Memory |
演进逻辑:从易失、具体的工作记忆,到持久、抽象的参数/长期记忆,形成了一个完整的记忆层次结构。
这是图的纵向次要分类轴,描述了记忆在智能体中的应用场景和目标:
| 功能类别 | 核心目标 | 代表模块 |
|---|---|---|
| 上下文管理 | 压缩、筛选、组织当前对话或任务的上下文,以突破模型长度限制。 | Context Condensation , ContextFolding , SnapKV , PyramidKV |
| 经验内化 | 从过往的交互(成功或失败)中学习,形成可复用的策略或知识。 | Internalizing Experiences , Chain-of-Agent , RAGEN |
| 知识提取与洞察 | 从海量信息中主动发现模式、规律和新知识。 | Extract Insights , IterResearch |
| 工具使用记忆 | 记住如何调用API、使用工具,并记录其结果。 | ToolMem , ChemAgent , GUI Memory |
| 世界模型构建 | 形成对环境和物理/社会规律的内部表征。 | WorldM , KΛIST , VideoAgent |
| 持续学习与适应 | 在不遗忘旧知识的前提下,不断整合新信息。 | CoMEM , Continuous , Trainable |
图的核心区域布满了具体的AI智能体系统或模块名称,它们被放置在其主要采用的记忆形式和主要实现的记忆功能的交叉区域。
例如:
总而言之,这张图是AI智能体记忆技术的“地图”和“指南”。它告诉研究者:
这为设计和评估新一代具有更强记忆能力的AI智能体提供了一个非常清晰、实用的理论框架。

当基于LLM的智能体与环境交互时,其瞬时观测值往往不足以进行有效决策。因此,Agent依赖从先前的交互中获得的额外信息,无论是当前任务内部还是在以前完成的任务之间。我们通过一个统一的代理记忆系统将这种能力形式化,表示为一个不断演化的记忆状态。
这种记忆系统没有施加特定的内部结构;它可以采用文本缓冲区、键值存储、向量数据库、图结构或任何混合表示的形式。在任务开始时,Mt可能已经包含了从先前轨迹中提取的信息(跨试次记忆)。在任务执行过程中,新的信息积累并作为短期的、任务特定的记忆发挥作用。这两种角色都在单一的记忆容器中得到支持,时间上的区别来自于使用模式,而不是架构上的分离。
智能体记忆不是一个静态仓库,而是一个“形成-演化-检索” 的动态循环系统。其核心要点如下:
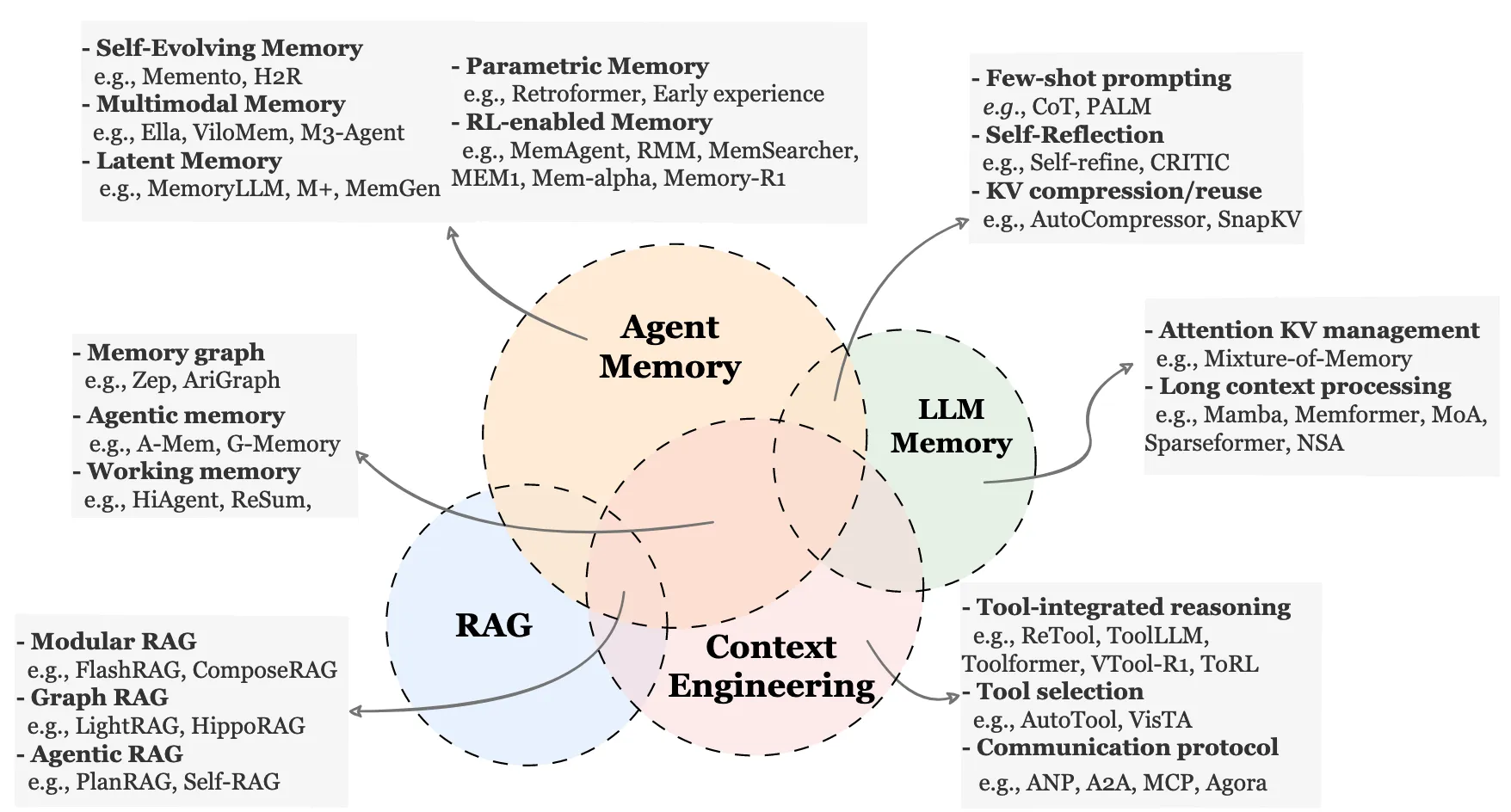
在不同的Agent系统中,记忆并不是通过单一的、统一的结构来实现的。相反,不同的任务设置需要不同的存储形式,每种存储形式都有自己的结构属性。这些架构赋予了记忆不同的能力,塑造了智能体如何通过交互积累信息并保持行为一致性。它们最终使记忆能够在不同的任务场景中完成其预定的角色。

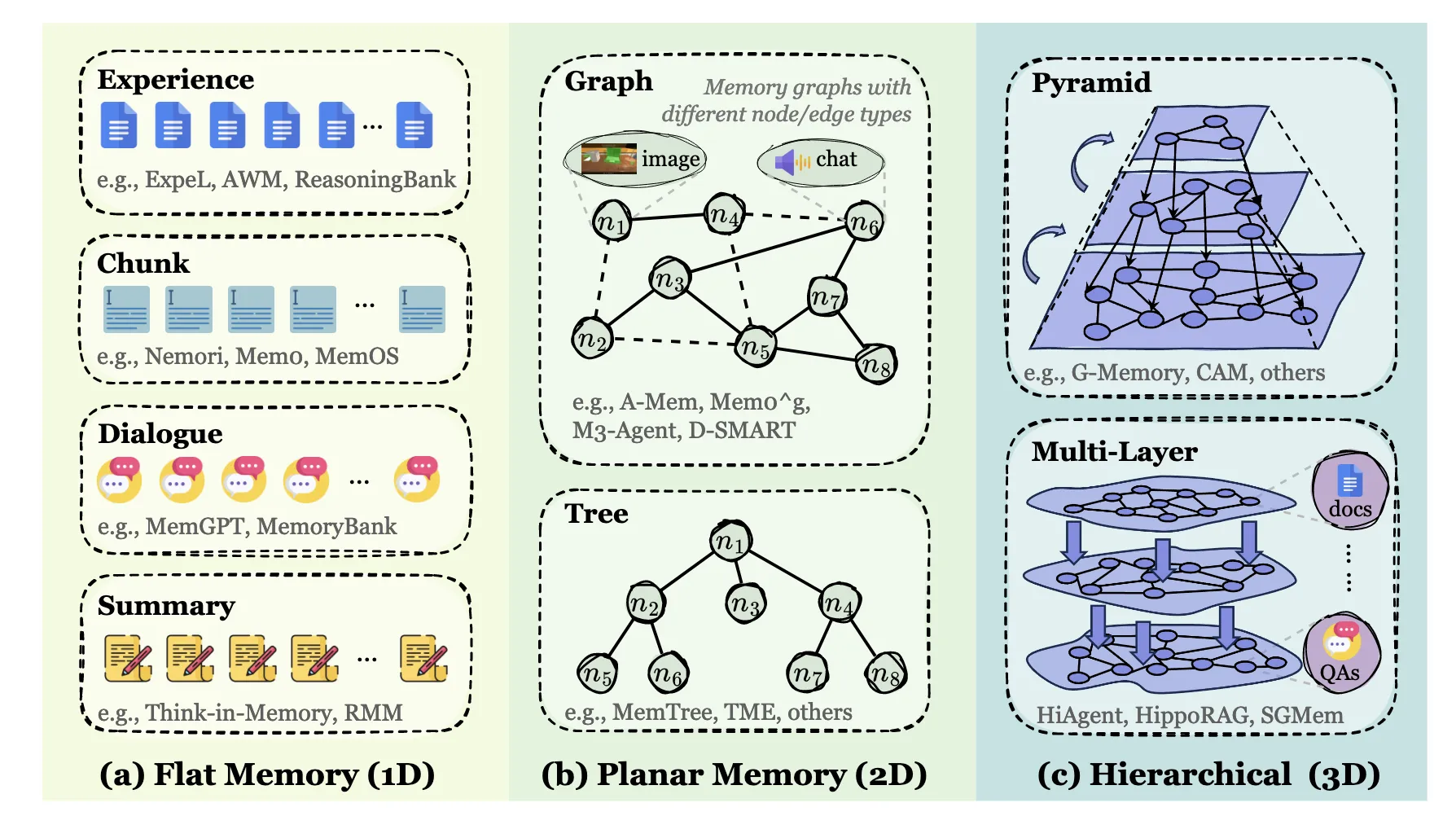
Token级记忆:以离散、外部可访问的单元(如文本块、向量、图节点)存储信息。这是最常见的形式,可进一步按组织结构分为:
平面记忆( Planar Memory )引入了记忆单元之间的显式组织拓扑,但仅限于单个结构层内,简称为2D。拓扑可能是图、树、表、隐式连接结构等,其中邻接、父子序或语义分组等关系编码在一个平面内,没有层次或跨层引用。
参数记忆:信息编码在模型参数内部,通过前向计算隐式访问。
参数记忆的两种主要类型
1 .内部参数记忆:在模型( e.g. ,权重,偏差)的原始参数内编码的记忆。这些方法直接对基模型进行调整,以纳入新的知识或行为。
2 .外部参数存储器:存储在额外或辅助参数集合中的存储器,如适配器、LoRA模块或轻量级代理模型。这些方法在不修改原有模型权重的前提下,引入新的参数进行记忆。
潜在记忆:信息存在于模型的内部隐藏状态或连续的潜在表示中,在推理过程中持续和演化。
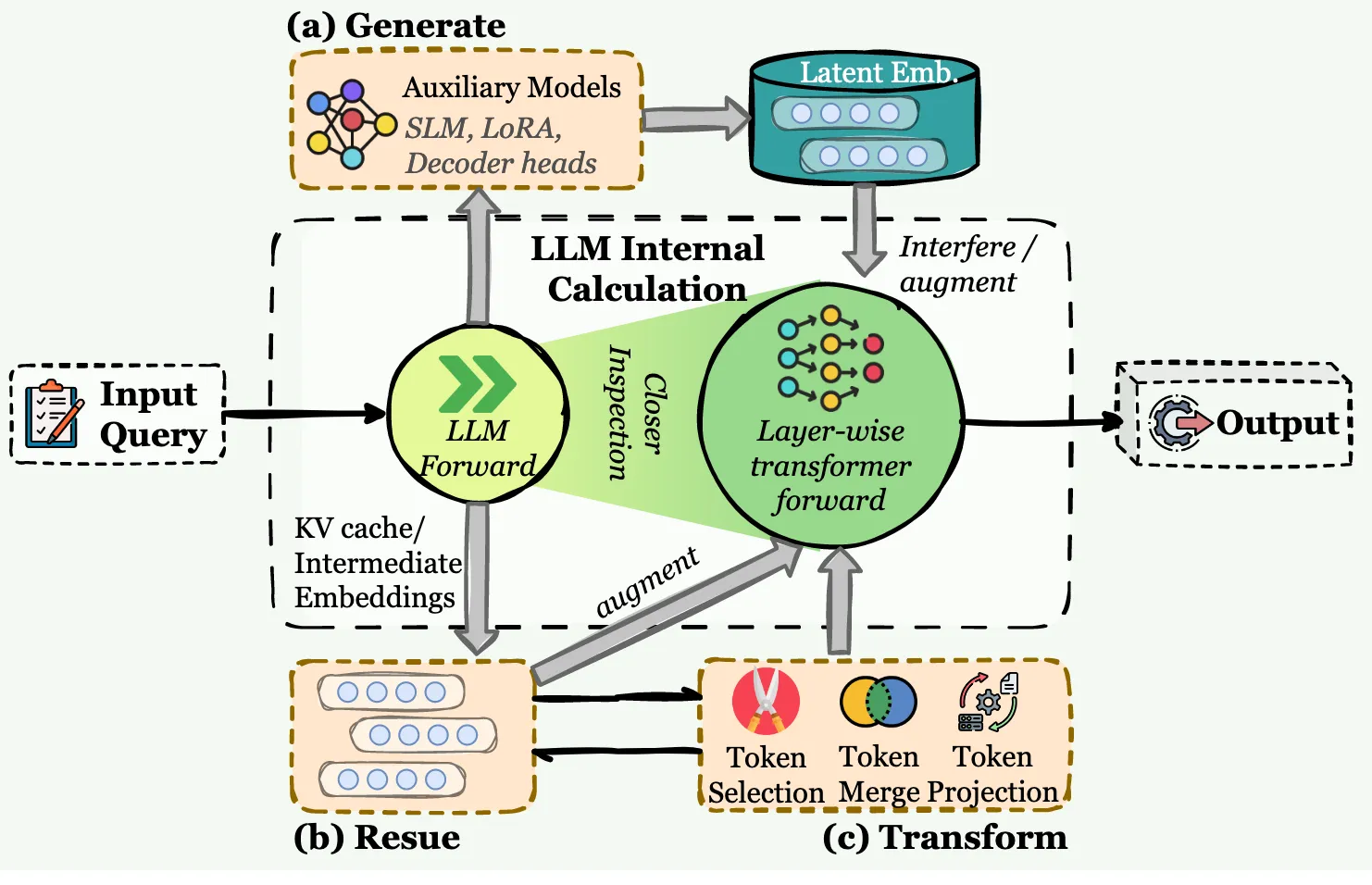
LLM代理中的潜在内存集成概述。与显式文本存储不同,潜在记忆在模型的内部表征空间进行操作。该框架根据隐状态的来源进行分类:
( a )生成,其中辅助模型合成嵌入,以干扰或增强LLM的前向传递;
( b )重复使用,它直接传播先验计算状态,如KV缓存或中间嵌入;
( c ) Transform,它通过令牌选择、合并或投影来压缩内部状态,以保持有效的上下文。
根据定义,智能体必须随着时间的推移而持续、适应和一致地交互。实现这一点不仅依赖于一个大的语境窗口,而且从根本上取决于记忆的容量。
三个主要记忆功能
1 .Factual Memory 事实记忆:智能体的陈述性知识基础,通过回忆明确的事实、用户偏好和环境状态来确保一致性、连贯性和适应性。这个系统回答了"智能体知道什么"的问题。
2 .Exp Memory 经验记忆:行动者的程序性和策略性知识,通过从过去的轨迹、失败和成功中抽象出来而积累起来,以使其能够持续学习和自我进化。这个系统回答:"智能体如何改进"
3 .Working Memory 工作记忆:智能体的容量限制,动态控制的画板,用于在单个任务或会话期间进行主动的上下文管理。这个系统回答:'智能体现在在想什么'
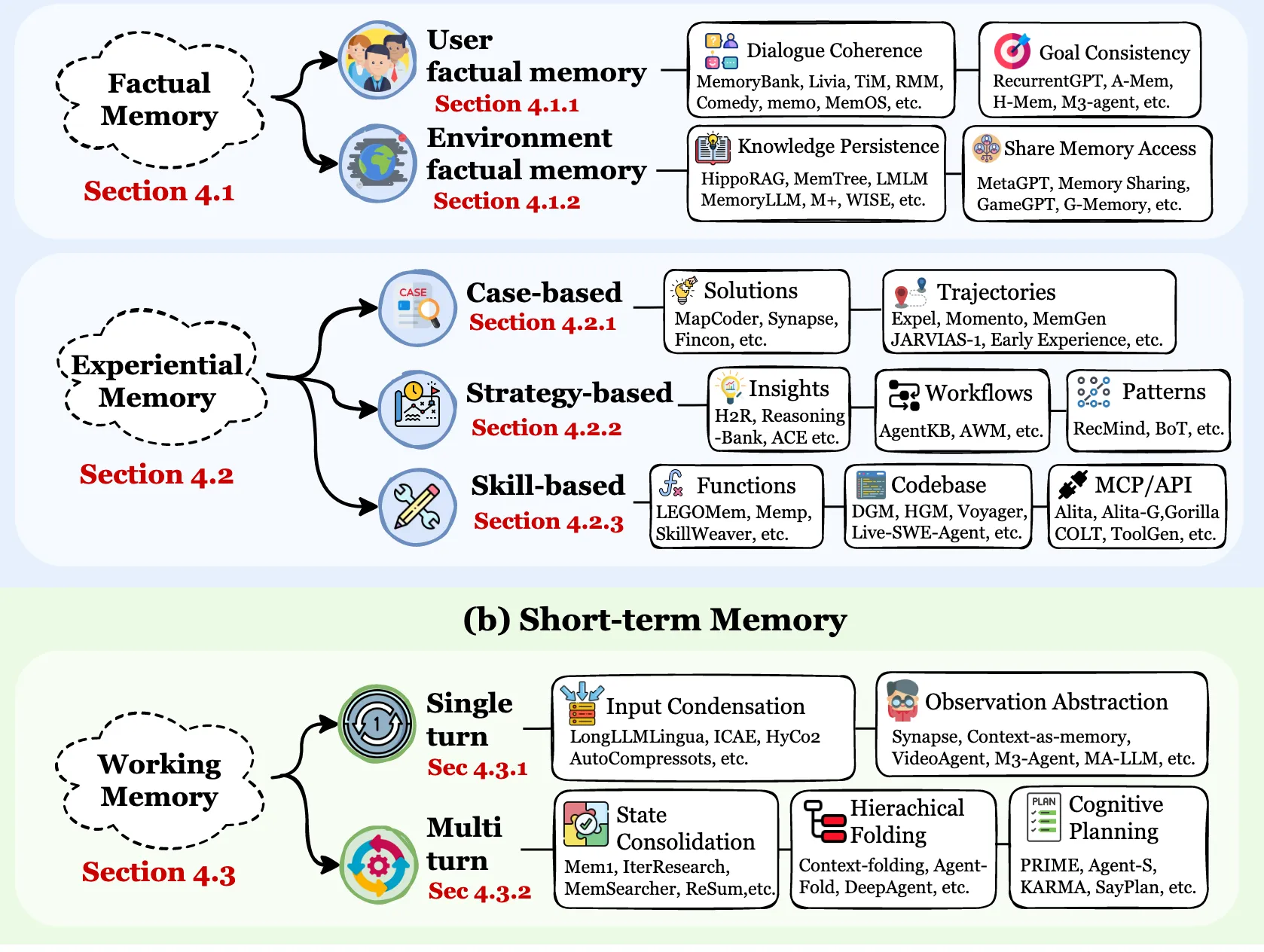
这部分是智能体持久化的“大脑皮层”,存储着长期、稳定的信息。它被分为两大类:
存储关于世界和用户的客观事实。
存储智能体亲身实践过的行动和思考过程,类似于人类的“阅历”。
这部分相当于智能体的“桌面”或“思维缓存”,处理当前任务相关的即时信息。它容量有限,但高度活跃和动态。
前几节介绍了记忆的架构形式(第3节)和功能角色(第4节),勾勒出一个相对静态的主体记忆概念框架。然而,这种静态的观点忽略了根本上表征施事记忆的内在动态性。与静态编码在模型参数或固定数据库中的知识不同,代理记忆系统可以动态地构建和更新其记忆库,并根据不同的查询执行定制的检索。
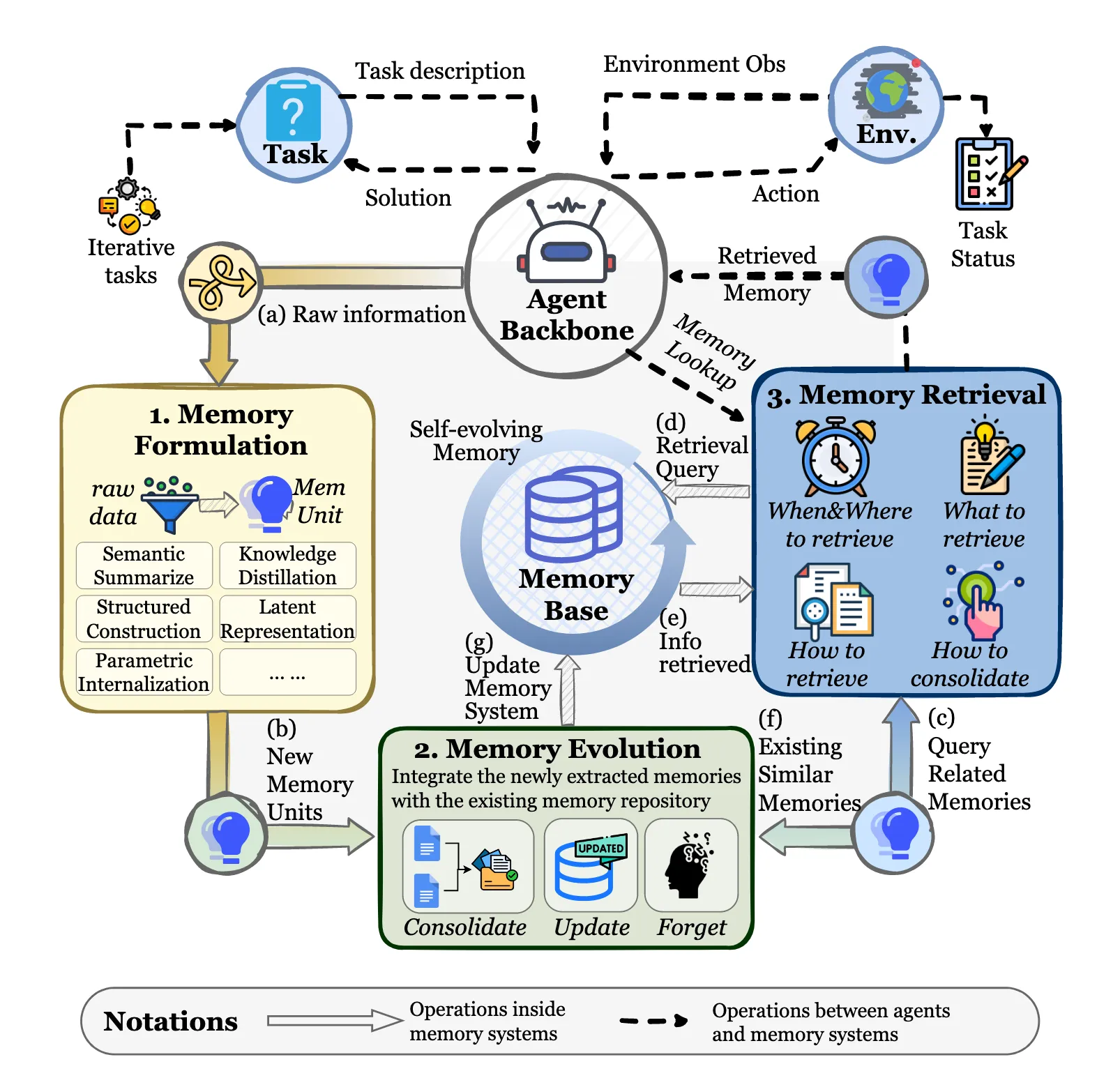
记忆系统中的三个基本过程
1 . MemoryForformation:这个过程着重于将原始经验转化为信息密集的知识。记忆系统不是被动地记录所有的交互历史,而是有选择地识别具有长期效用的信息,如成功的推理模式或环境约束。这一部分回答了"如何提取记忆"的问题。
2 . Memory Evolution:这个过程代表了记忆系统的动态演化。它注重将新形成的记忆与已有的记忆基础进行整合。 该系统通过相关词条的合并、冲突解决、自适应剪枝等机制,保证了记忆在不断变化的环境中保持可泛化、连贯和高效。这一部分回答了"如何提炼记忆"的问题。
3 .内存检索:这个过程决定了检索到的内存的质量。在上下文的条件下,系统构建了一个任务感知的查询,并使用精心设计的检索策略来访问相应的内存库。因此,提取的记忆对推理既是语义相关的,也是功能关键的。这一部分回答了"如何利用记忆"的问题。
智能体的“智能”主要体现在它能利用过去、指导现在、优化未来。这三个模块共同构成了一个完整的“学习-记忆”闭环。
目的:不是简单地记录所有聊天记录,而是像人类做笔记一样,从原始交互数据中提炼出有价值、可复用的“知识单元”。
输入(a):原始对话、工具输出、任务结果等。
处理过程:
输出(b):结构化的、语义清晰的 “新记忆单元”。
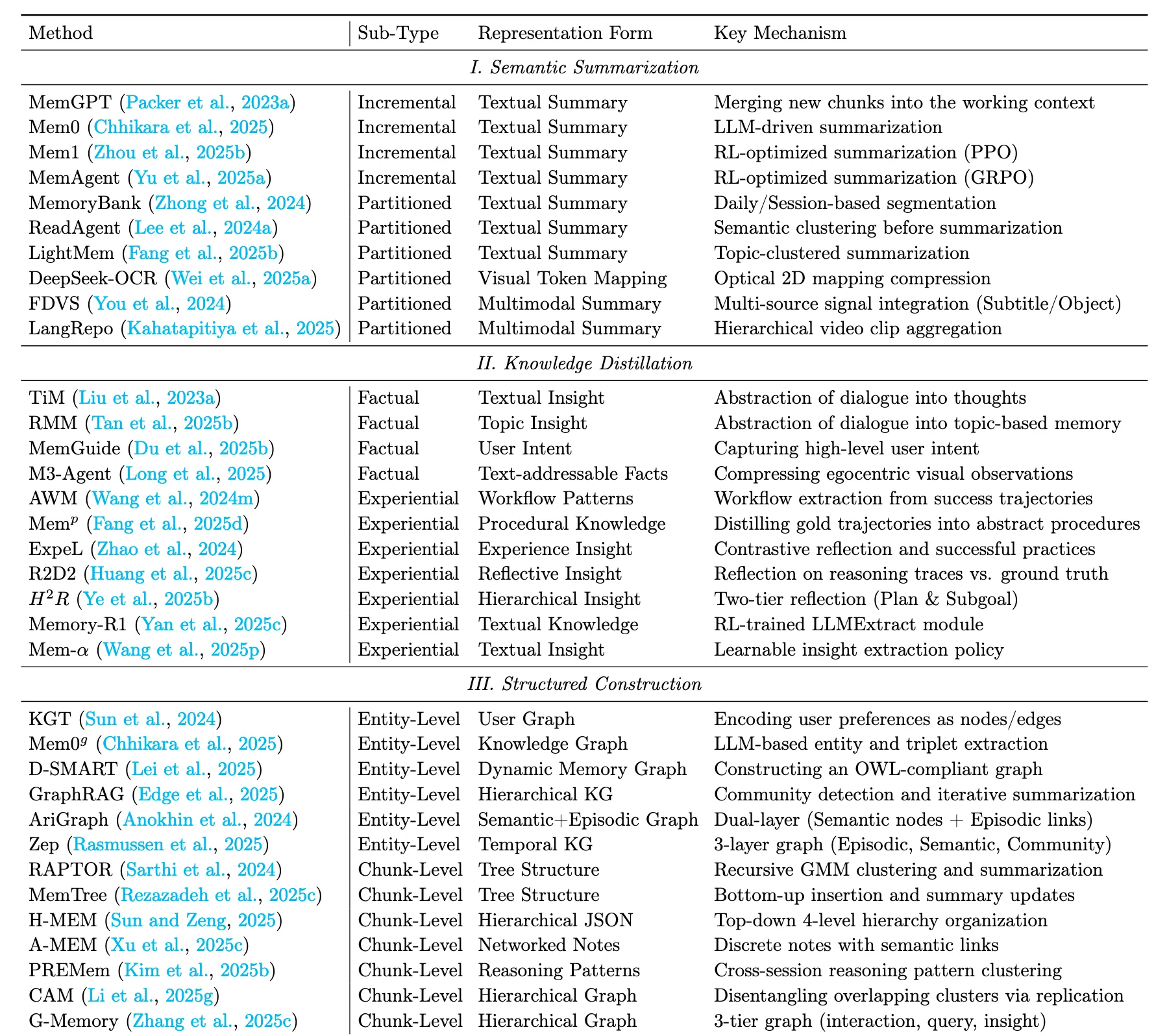
Summary Semantic summarization operates as a lossy compression mechanism, aiming to distill the gist from lengthy interaction logs. Unlike verbatim storage, it prioritizes global semantic coherence over local factual precision, transforming linear streams into compact narrative blocks. The primary strength of semantic summarization is efficiency: it drastically reduces context length, making it ideal for long-term dialogue. However, the trade-off is resolution loss: specific details or subtle cues may be smoothed out, limiting their utility in evidence-critical tasks.
该范式采用时间整合机制,不断将新观察到的信息与已有的摘要进行融合,产生了一种不断演化的全局语义表示。
该范式采用空间分解机制,将信息划分为不同的语义分区,并为每个分区生成单独的摘要。早期的研究通常采用启发式的划分策略来处理长语境。
Summary:The main advantage of structured construction is explainability and the ability to handle complex relational queries. Such methods capture intricate semantic and hierarchical relationships between memory elements, support reasoning over multi-step dependencies, and facilitate integration with symbolic or graph-based reasoning frameworks. However, the downside is schema rigidity: pre-defined structures may fail to represent nuanced or ambiguous information, and the extraction and maintenance costs are typically high.
该范式的基础结构来源于关系三元组抽取,它将原始上下文分解为其最细粒度的语义原子实体和关系。传统方法将记忆建模为平面知识图谱。
该范式将连续的文本跨度或离散的记忆项作为节点,在保持局部语义完整性的同时将其组织成拓扑结构。该领域的发展经历了从静态的、平面的( 2D )从固定语料中提取,到动态地适应新的轨迹,最终发展到分层的( 3D )架构。
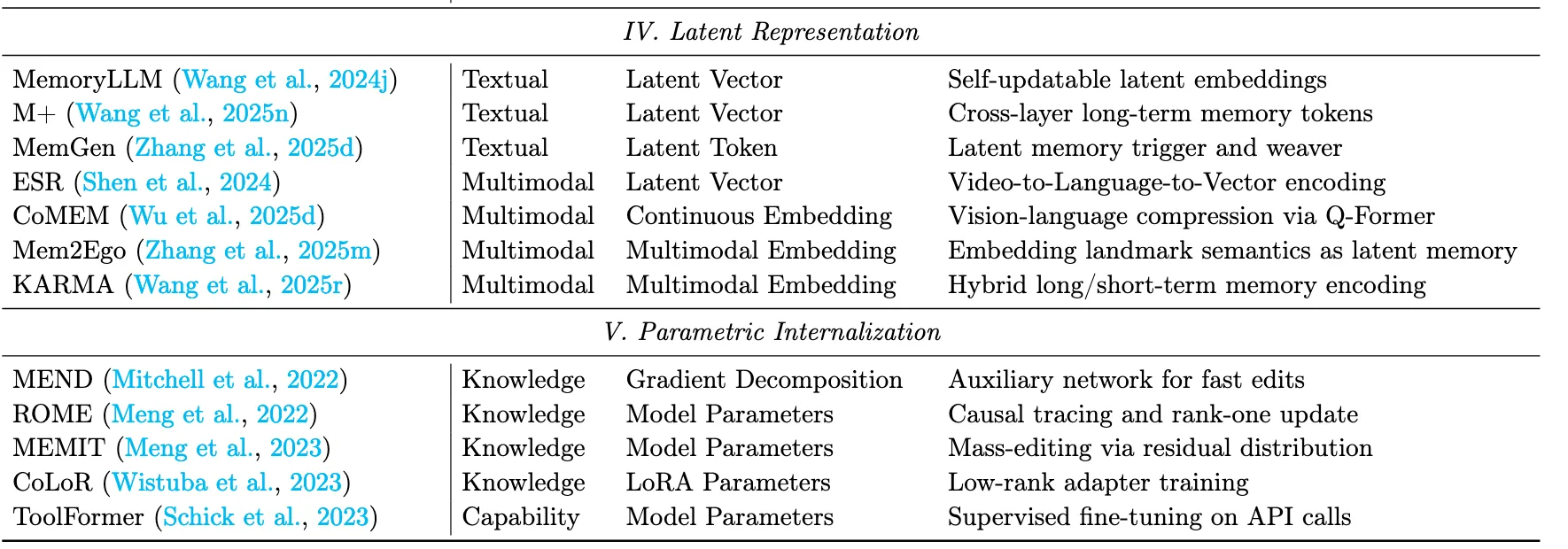
Summary:Parametric internalization represents the ultimate consolidation of memory, where external knowledge is fused into the model’s weights via gradients. This shifts the paradigm from retrieving information 54 to possessing capability, mimicking biological long-term potentiation. As knowledge becomes effectively instinctive, access is zero-latency, enabling the model to respond immediately without querying external memory. However, this approach faces several challenges, including catastrophic forgetting and high update costs. Unlike external memory, parameterized internalization is difficult to modify or remove precisely without unintended side effects, limiting flexibility and adaptability.
这一策略需要将外部存储的事实记忆,如概念定义或领域知识,转换到模型的参数空间中。通过这个过程,模型可以直接回忆和利用这些事实,而不需要依赖显式检索或外部记忆模块。
能力内化这一策略旨在将经验知识,如程序性专业知识或战略启发式知识,嵌入到模型的参数空间中。该范式代表了一种广义上的记忆形成操作,从事实性知识的获得转向经验能力的内化。具体来说,这些能力包括特定领域的解决方案模式、战略规划以及Agent技能的有效部署等。从技术上讲,能力内化是通过从推理轨迹中学习,通过有监督的微调( Wei et al , 2022 ; Zelikman et al , 2022 ; Schick et al , 2023 ;慕克吉et al , 2023)或偏好引导的优化方法,如DPO (拉斐洛夫等)来实现的 2023年;滕斯托尔et al,2023;Yuan et al .,2024c;Grattafiori et al,2024 )和GRPO (邵敏等, 2024 ; DeepSeek-AI et al , 2025)。作为将外部RAG与参数化训练相融合的尝试,Memory Decoder ( Cao et al , 2025a)是一种即插即用的方法,它不像外部RAG那样修改基模型,同时通过消除外部检索开销来实现参数内化的推理速度。这种即插即用的参数化记忆可能具有广泛的潜力。
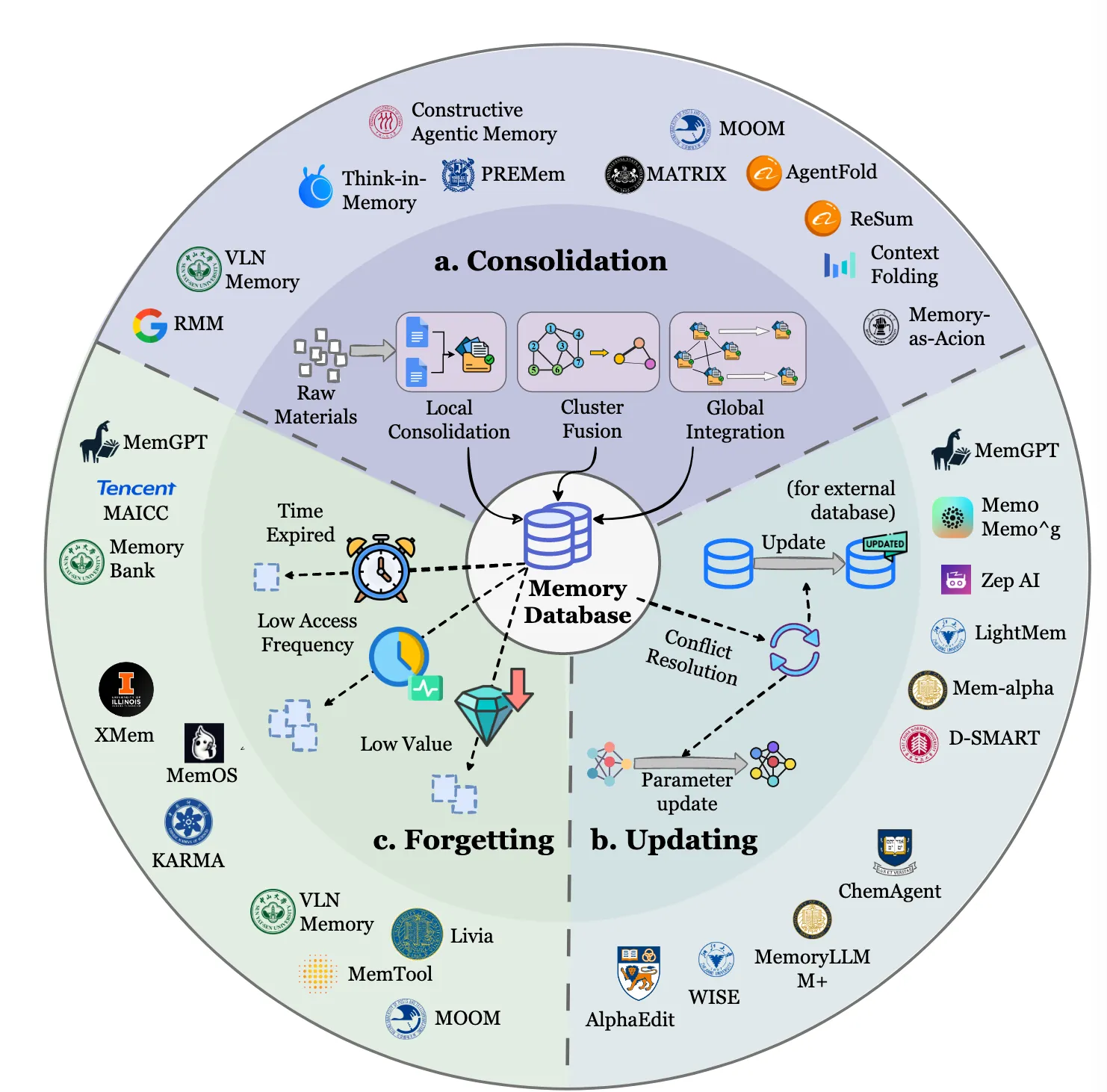
目的:管理记忆库,使其像一个不断成长的智库,而不是一个杂乱无章的仓库。通过整合、去重、更新,确保知识的质量和可用性。
输入(g):从模块1来的新记忆单元。
处理过程:
记忆进化的三种机制
Consolidation is the cognitive process of reorganizing fragmented short-term traces into coherent long-term schemas. It moves beyond simple storage to synthesize connections between isolated entries, forming a structured worldview. It enhances generalization and reduces storage redundancy. However, it risks information smoothing, where outlier events or unique exceptions are lost during the abstraction process, potentially reducing the agent’s sensitivity to anomalies and specific events.
将新的和已有的记忆进行融合,进行反思性整合,形成更一般化的洞见。这确保了学习是累积的而不是孤立的。
Summary:From an implementation standpoint, memory updating focuses on resolving conflicts and revising knowledge triggered by the arrival of new memories, whereas memory consolidation emphasizes the integration and abstraction of new and existing knowledge. The two memory updating strategies discussed above establish a dual-pathway mechanism involving conflict resolution in external databases and parameter editing within the model, enabling agents to perform continuous self-correction and support long-term evolution. The key challenge is the stability–plasticity dilemma: determining when to overwrite existing knowledge versus when to treat new information as noise. Incorrect updates can overwrite critical information, leading to knowledge degradation and faulty reasoning.
解决了新的和现有内存之间的冲突,纠正和补充了存储库,以保持准确性和相关性。它允许代理适应环境或任务需求的变化。
Summary Time-based decay reflects the natural temporal fading of memory, frequency-based forgetting ensures efficient access to frequently used memories, and importance-driven forgetting introduces semantic discernment. These three forgetting mechanisms jointly govern how agentic memory remains timely, efficiently accessible, and semantically relevant. However, heuristic forgetting mechanisms like LRU may eliminate long-tail knowledge, which is seldom accessed but essential for correct decision-making. Therefore, when storage cost is not a critical constraint, many memory systems avoid directly deleting certain memories.
删除过时或冗余的信息,释放容量,提高效率。这样可以防止由于知识过载而导致的性能下降,并确保内存存储库仍然专注于可操作的和当前的知识。
基于时间的衰减反映了记忆的自然时间衰减,基于频率的遗忘保证了对经常使用的记忆的有效访问,而重要性驱动的遗忘引入了语义辨别。这三种遗忘机制共同决定了施事记忆如何保持及时、有效和语义相关。然而,LRU等启发式遗忘机制可能会消除长尾知识,而这些知识很少被访问,但对于正确决策至关重要。因此,当存储开销不是一个关键的限制条件时,许多存储系统避免直接删除某些内存。
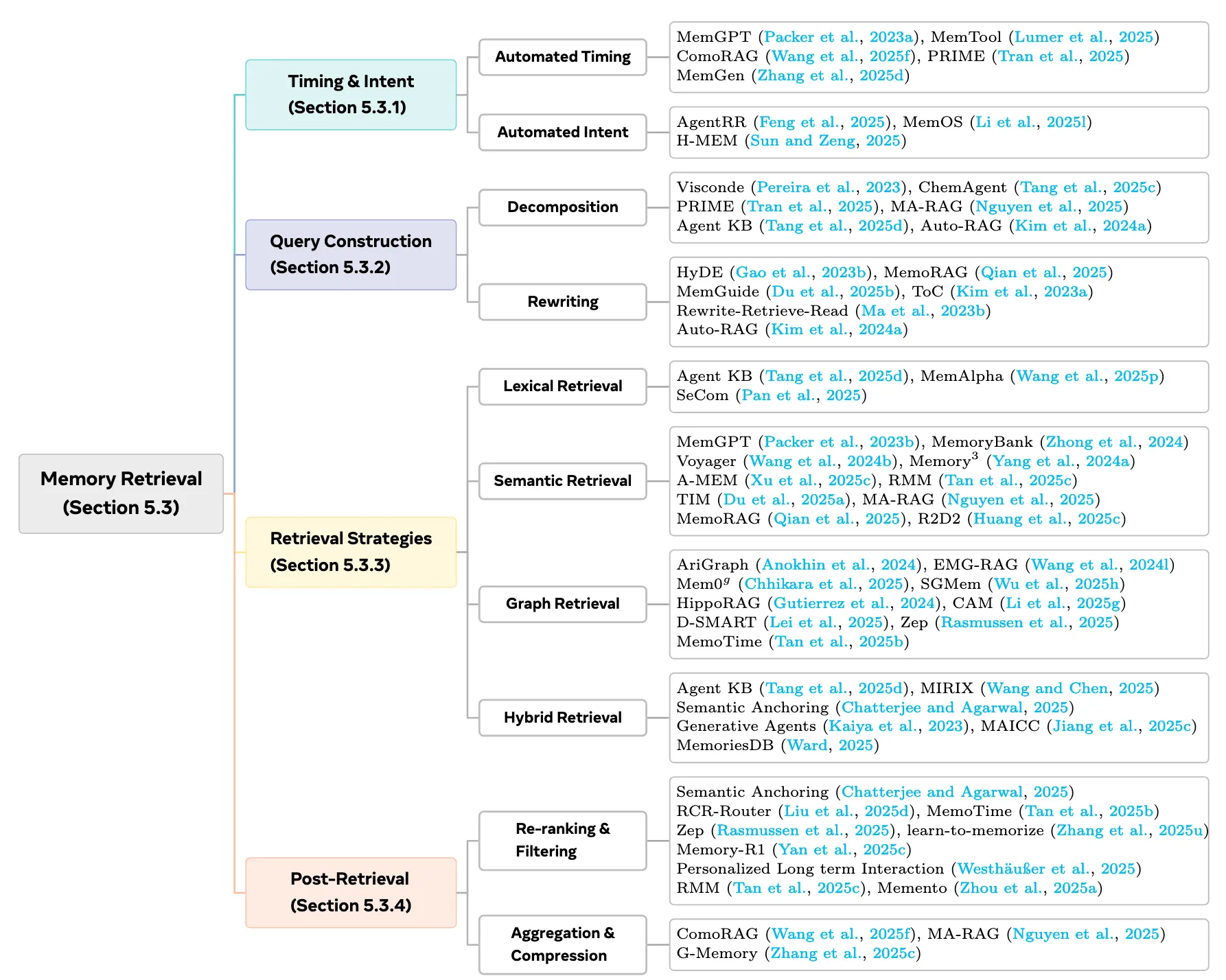
目的:当智能体面对新任务时,它能主动、精准地从庞大的记忆库中召回最相关的经验来辅助决策。
Summary: Autonomous timing and intent help reduce computational overhead and suppress unnecessary noise, but they also create a potential vulnerability. When an agent overestimates its internal knowledge and fails to initiate retrieval when needed, the system can fall into a silent failure mode in which knowledge gaps may lead to hallucinated outputs. Therefore, a balance needs to be achieved: providing the agent with essential information at the right moments while avoiding excessive retrieval that introduces noise.
自动检索时机这一术语是指模型在推理过程中自主决定何时触发记忆检索操作的能力。最简单的策略是将决策委托给LLM或外部控制器,允许其仅从查询中确定是否需要检索。自动检索意图这一方面涉及模型自主决定在一个层次的存储形式中访问哪个内存源的能力。
These two paradigms, decomposition and rewriting, are not mutually exclusive. Auto-RAG (Kim et al., 2024a) integrates both by evaluating HyDE and Visconde under identical retrieval conditions and then selecting the strategy that performs best for the given task. The findings of this work demonstrate that the quality of the memory-retrieval query has a substantial impact on reasoning performance. In contrast to earlier research, which primarily focused on designing sophisticated memory architectures, recent studies (Yan et al., 2025b) place increasing emphasis on the retrieval construction process, shifting the role of memory toward serving retrieval. The choice of what to retrieve with is, unsurprisingly, a critical component of this process.
初始检索通常返回冗余的、有噪声的或语义不一致的片段。直接将这些结果注入提示中,会导致上下文过长、信息冲突、推理被无关内容干扰等问题。因此,检索后的处理对于确保及时的质量至关重要。它的目标是将检索到的结果提取到一个简洁、准确、语义连贯的上下文中。在实际应用中,有两个组成部分是核心的:
( 1 )重排序和过滤:执行细粒度的相关性估计,以删除不相关或过时的记忆,并对剩余的片段进行重新排序,从而减少噪声和冗余。
( 2 )聚合与压缩:将检索到的内存与原始查询进行整合,消除重复,合并语义相似的信息,重建紧凑连贯的最终上下文。
大家感兴趣可以去看看原论文噢:https://arxiv.org/pdf/2512.13564
这篇综述的代码仓库链接:https://github.com/Shichun-Liu/Agent-Memory-Paper-List

 关注微信
关注微信