时间:2025-09-03 15:03
人气:
作者:admin
从 Web 1.0 到 Web2.0,再到单页应用 (SPA) 和 React/Vue 等前端框架时代,再到当下的 AI Agent 时代。每个阶段都有当时的浏览器自动化的王者。
Selenium 的时代诞生于 Web 1.0 和 2.0 初期,当时网页主要是静态或多页面应用。Selenium 的架构基于命令驱动、需要显式等待,这完美契合了那个时代可预测的、步骤化的测试流程。
作为最早的行业标准,Selenium 的核心是 WebDriver 协议。该协议充当了测试脚本和浏览器驱动程序之间的中间层,通过 HTTP 进行通信。这种架构虽然实现了广泛的跨浏览器和跨语言兼容性,但也引入了额外的网络开销,导致性能相对较低,且架构较为复杂。
虽然 Selenium 支持的语言(Java, Python, C#, Ruby, JavaScript 等)和兼容性(包括一些旧版浏览器,比如老IE)相对广泛,但是性能问题,复杂度问题使得使用 Selenium 构建的自动化脚本非常脆弱和不稳定,也无法满足当前各种具备“动态”属性的前端特性和需求。
随着单页应用 (SPA) 和 React/Vue 等前端框架的普及,Web 变得高度动态、异步和状态化。网页不再是简单的文档,而是复杂的应用程序。为了应对这种新的现实,Google Chrome 团队开发了Puppeteer。 Puppeteer 绕过了 WebDriver 协议,通过 WebSocket 直接与 Chrome DevTools Protocol (CDP) 通信。这种直接通信的方式极大地提升了执行速度和控制的可靠性。
显而易见,Puppeteer 的最大优势是与 Chrome/Chromium 浏览器的深度集成,这也是 Puppeteer 性能很好的核心原因,这让 Puppeteer 非常适合执行 Chrome 特定的自动化任务,如网页截图、PDF 生成、Web录制和性能分析等。
但是 Puppeteer 也有明显的劣势,核心还是在支持的语言和兼容性方面。目前只支持 JavaScript、Node.js 和 Chromium 生态,虽然也支持 Firefox,但其跨浏览器能力远不如 Selenium 或 Playwright 。
Playwright 由微软推出,其核心开发团队正是来自最初创建 Puppeteer 的团队。Playwright 沿用了与 CDP 类似的 WebSocket 直接通信架构,但将其扩展为了一个统一的协议,能够同时支持 Chromium、Firefox 和 WebKit (Safari) 三大主流浏览器引擎,且提供完全一致的 API。
在当前 AI Agent 的时代下,AI Agent 代表了更高维度的交互模式。AI Agent 不是在执行预设的脚本,而是在根据实时感知的页面状态进行动态决策。这种模式要求其底层的执行器必须具备极高的鲁棒性、稳定性和对异步环境的适应能力,以应对来自 Web 和 AI 推理过程的双重不确定性。而 Playwright 正是在这个大背景下诞生的,所以天然具备自动等待、工具链、面向现在 Web 框架的鲁棒性等特性,从而使其成为构建 AI Agent 的理想选择。
当下,AI Agent 的能力类比人类,所以任何一个人类用户能在浏览器中完成的事情,理论上都可以通过 Browser Tool 赋予 AI Agent 来完成。但是有很多网站、企业内部系统和在线服务都是为人类用户设计的图形界面,它们并没有提供专门为机器准备的 API 接口。所以,Browser Tool 可以使得 AI Agent 能够直接操作这些为人类设计的界面,从而极大地扩展了其能力范围。比如:
然而,AI Agent 的强大自主性同时也带来了很多安全问题:
参考:https://dev.to/polozhevets/are-browser-ai-agents-a-security-time-bomb-unpacking-the-risks-and-how-to-stay-safe-55fihttps://www.imperva.com/blog/the-rise-of-agentic-ai-uncovering-security-risks-in-ai-web-agents
综上所述,在沙箱环境(Sandbox)中运行 Browser Tool 或者 Browser Use Agent 就变的至关重要,只有在沙箱(Sandbox)提供的受控环境中,我们才有可能安全地释放 AI Agent 的潜力。
众所周知,沙箱环境(Sandbox)最基本的作用是充当一个与你的主机系统、主程序完全隔离的、受控的环境 。你可以把它想象成将 Browser Agent 放置在一个行为受到严格限制的安全房间里。所以,即使 AI Agent 被欺骗而“失控”,沙箱环境(Sandbox)也能将“爆炸半径”控制在内部,确保损害仅限于这个临时的、可随时销毁的环境。
在带大家实操构建 Browser Tool Sandbox 前,我对整体的架构和涉及到的组件,以及基于函数计算 FC 构建的 Browser Tool Sandbox 的优势先作以解释,让大家有初步的概念。

核心组件解释:
别看上面涉及到那么多的组件和概念,其实我们都已经封装好了,你只需要一键,就可以把 Browser Tool Sandbox 构建出来并使用。除了快捷的构建以外,基于函数计算 FC 构建的 Browser Tool Sandbox 还有其他的一些优势和特性:
登录阿里云账号,打开 FunctionAI 中的 Browser Tool Sandbox 模板,点击立即部署。


点击部署项目按钮,等待部署。
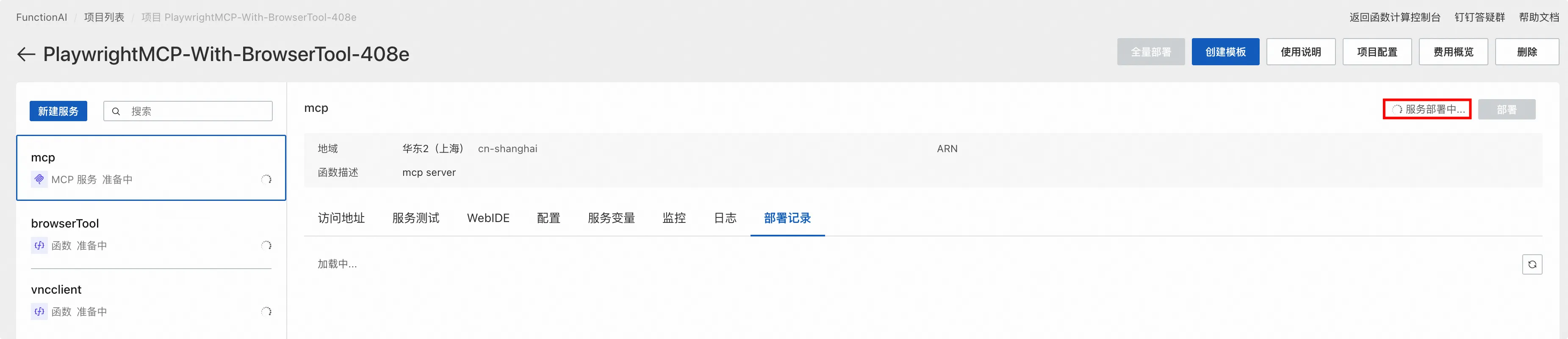
几分钟后,整个项目即可部署完成。
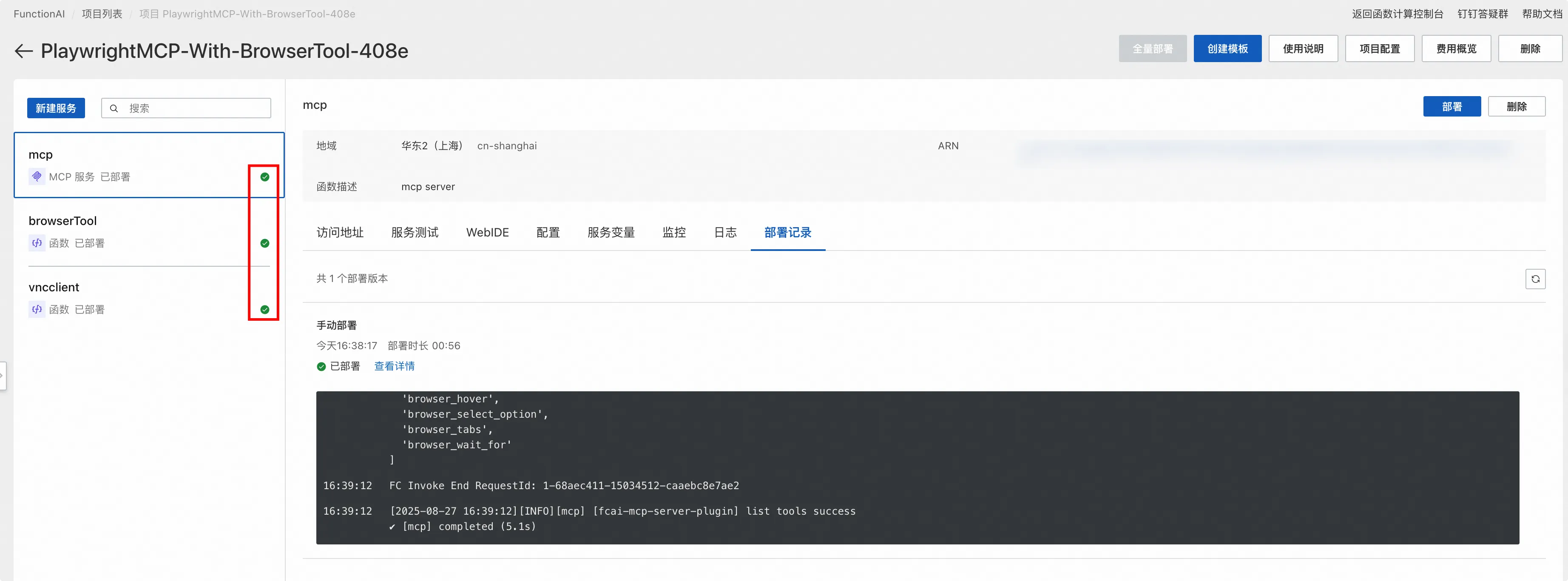
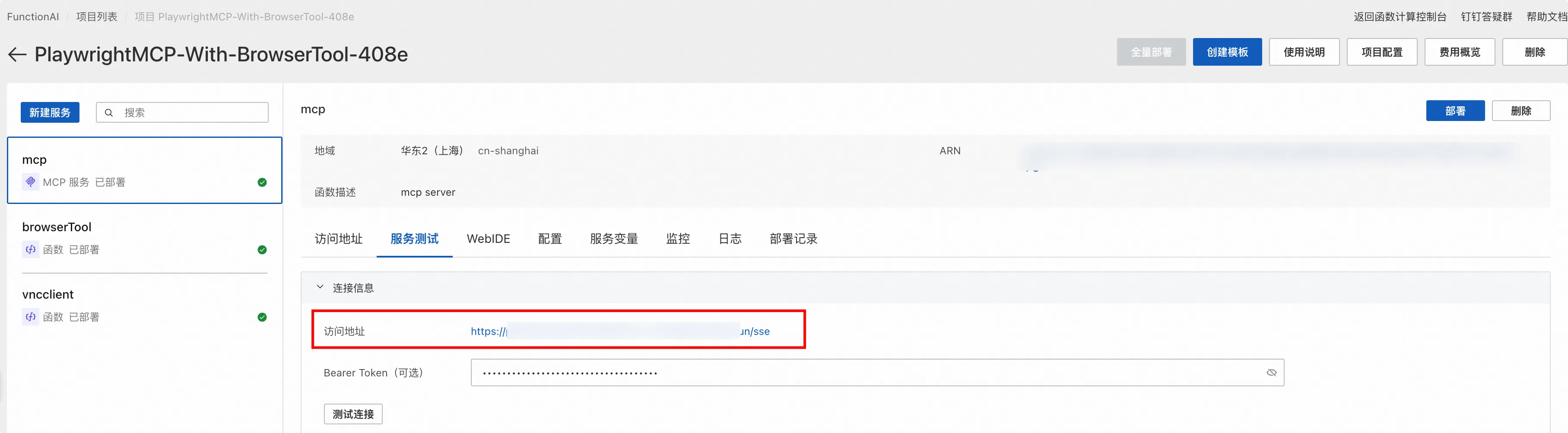
整个项目包含3个函数:
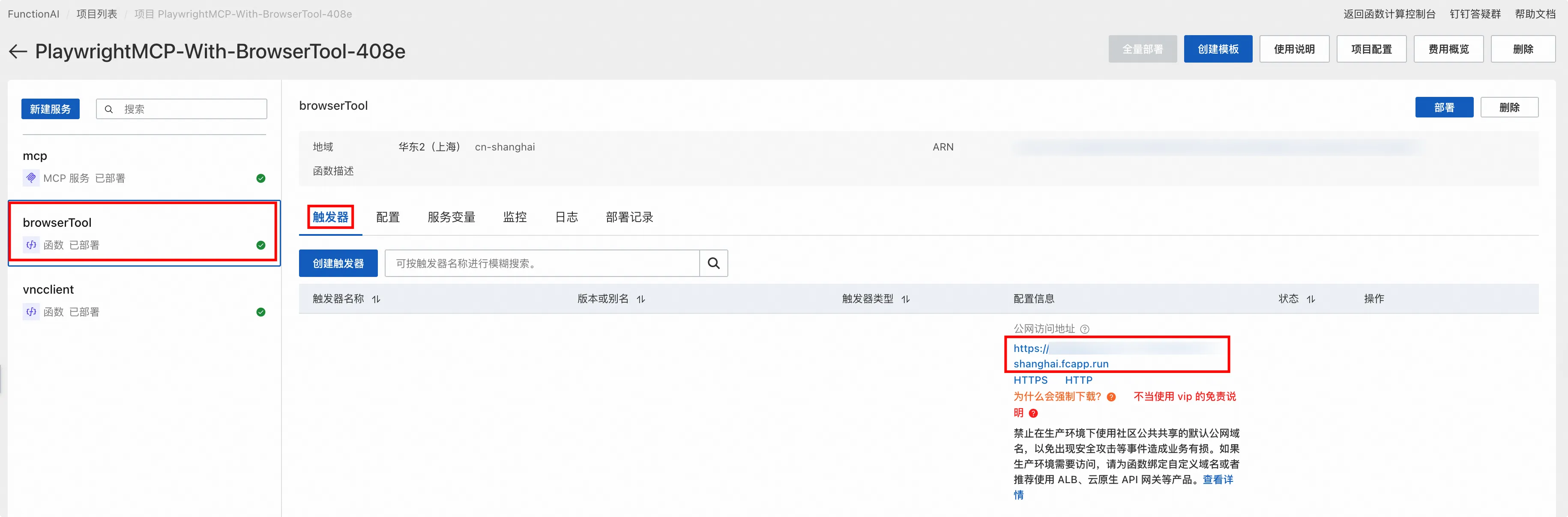
选择 nvcclient 函数,进入触发器页签,可以看到访问 NoVNC 客户端的公网地址和内网地址。

但是为了安全考虑,我们提供的默认域名不能直接在浏览器中访问,所以需要配合云原生 API 网关或者绑定自定义域名来使用。
进入配置页签,找到最下方的自定义域名,点击编辑进行配置。
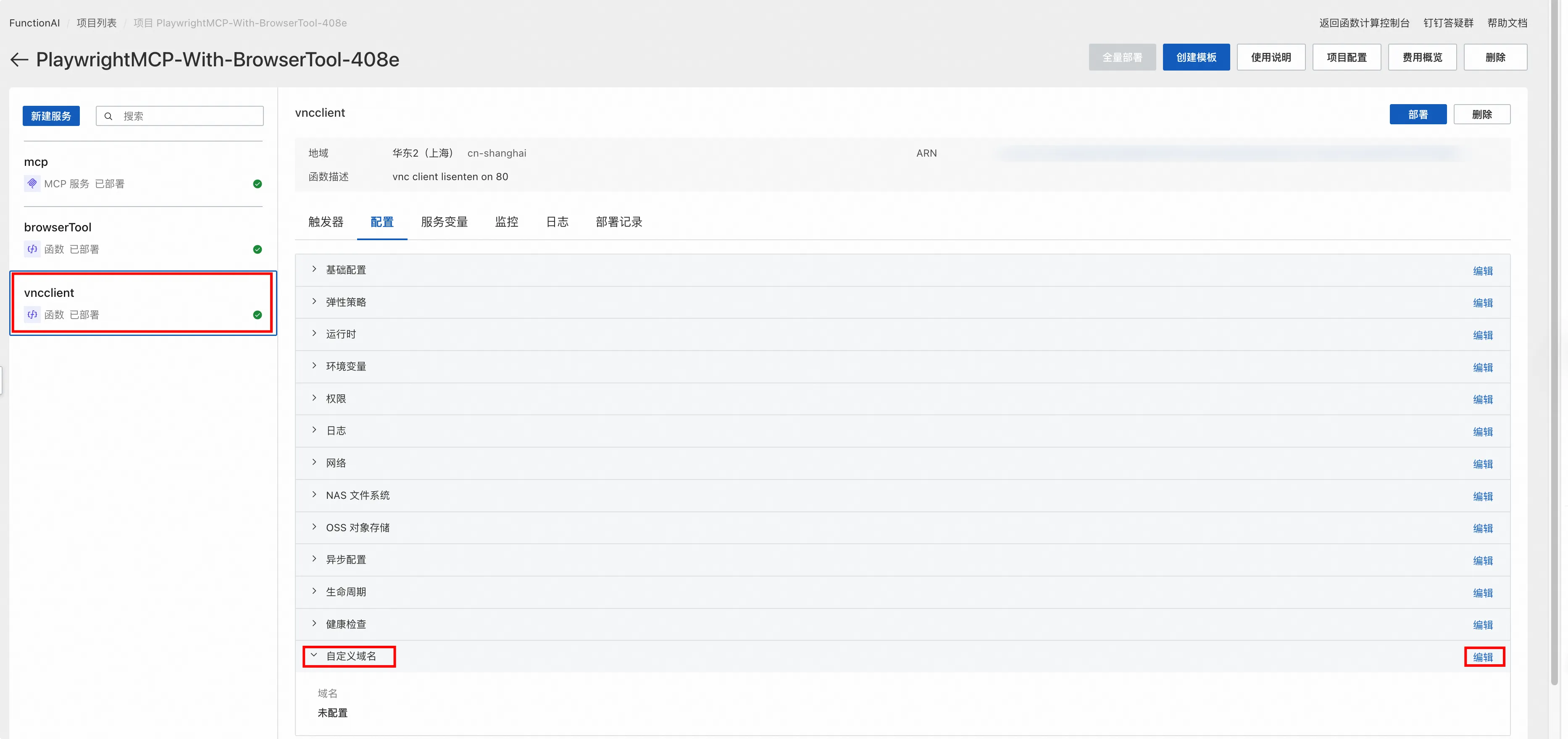
具体的配置方法可参见文档:配置自定义域名
当配置完自定义域名后可以看到该函数有变更,点击右上角部署按钮进行部署。
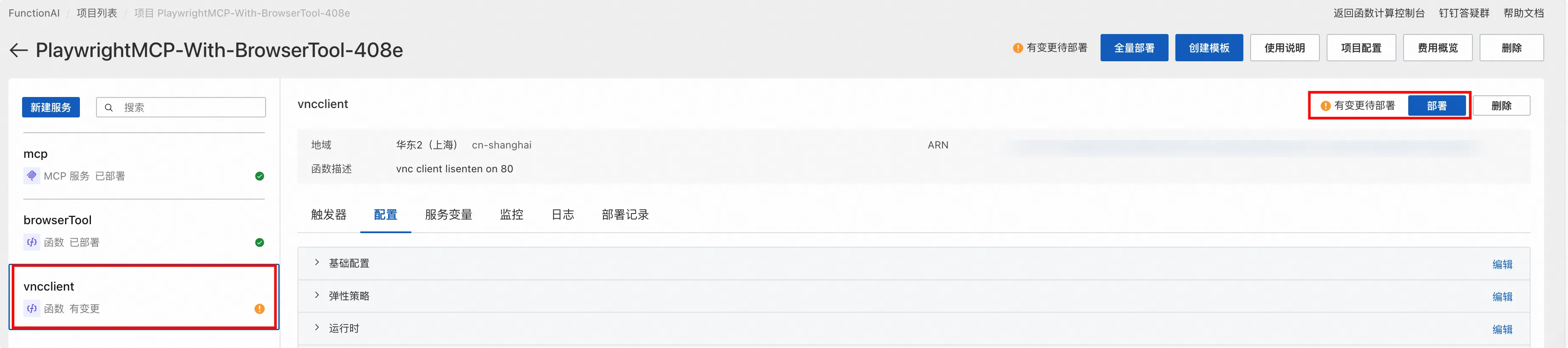
部署成功后,使用浏览器访问你绑定的自定义域名,便可以打开 NoVNC 客户端。

点击左侧配置按钮,在 WebSocket 中配置协议代理层的地址。
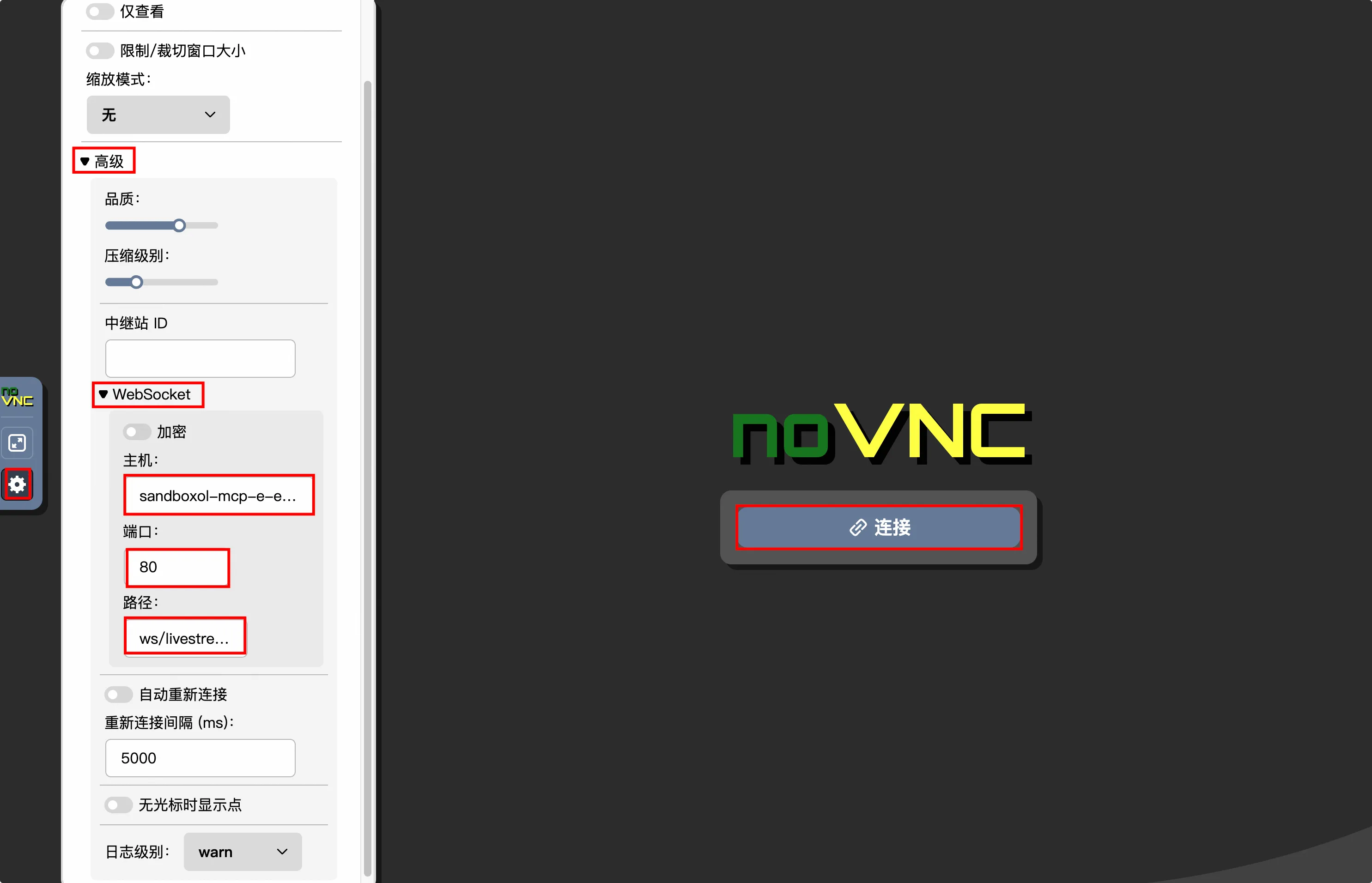
配置完后点击连接,便可以使 NoVNC 通过 RBF 协议连接到 x11VNC 服务了。
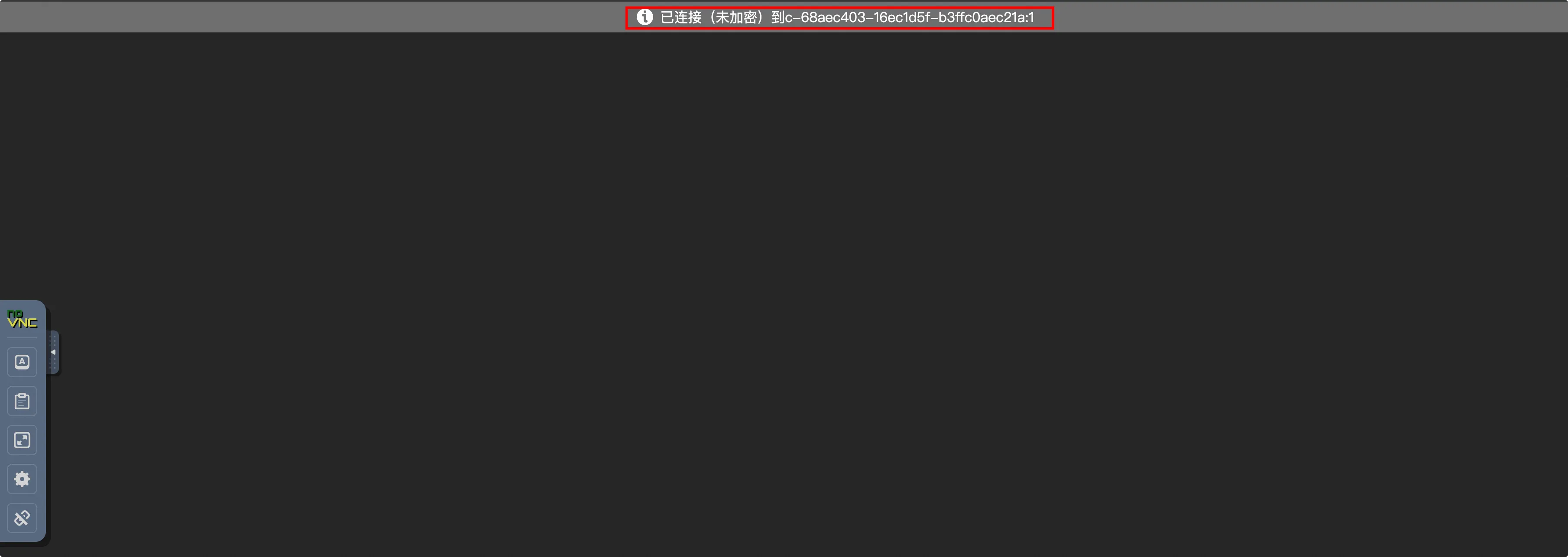
这里因为没有对浏览器做任何请求,所以看到的是黑屏,后续我们通过 Playwright 对浏览器做操作时,通过 NoVNC 就可以看到内容了。
文本中我使用 DeepChat 这个客户端来演示如何使用 Playwright MCP 操作浏览器。大家也可以使用其他的 MCP Client,配置 MCP 服务的方式都是一致的。
进入 DeepChat 的 MCP 服务设置界面,点击新增按钮。
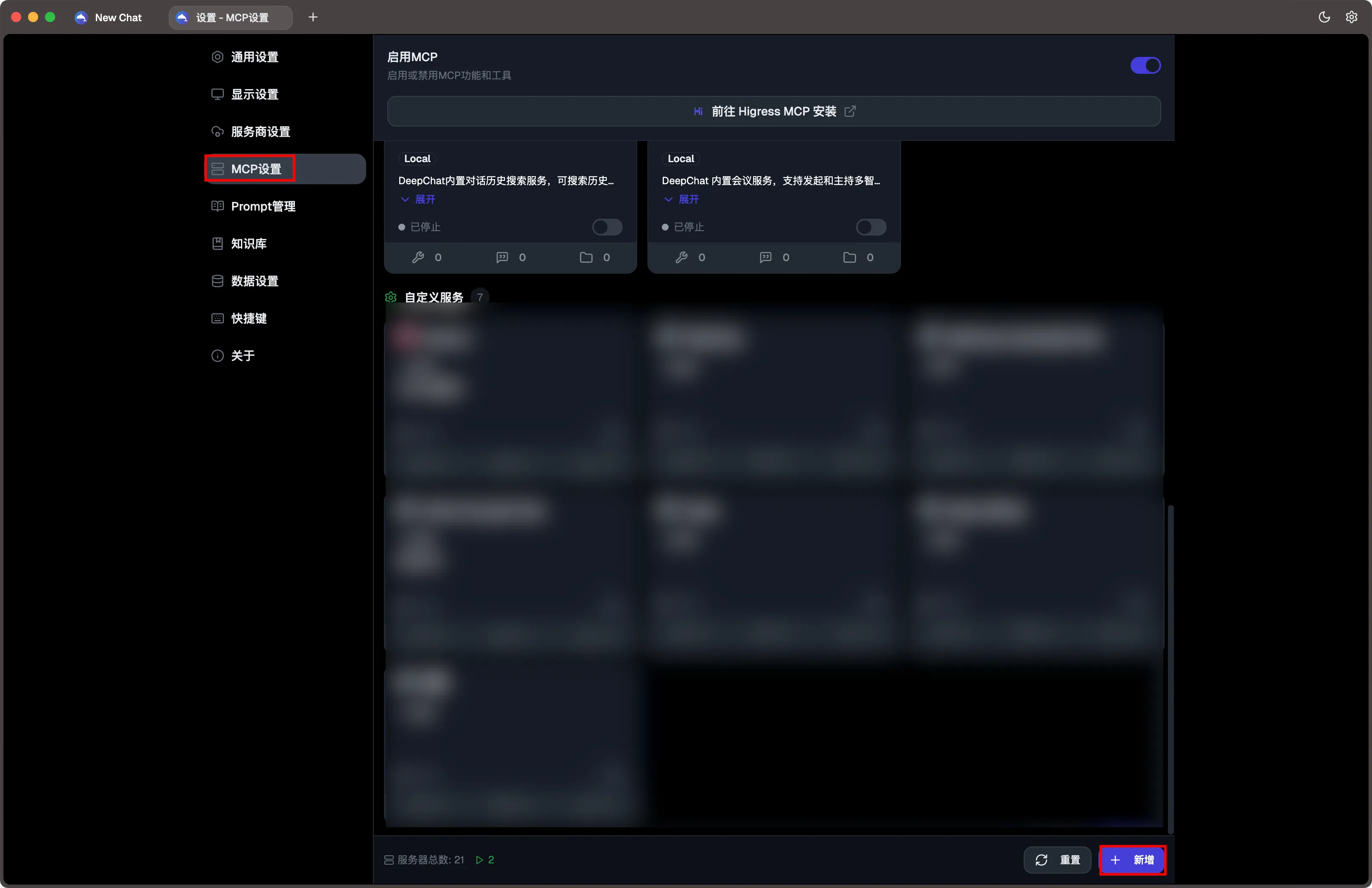
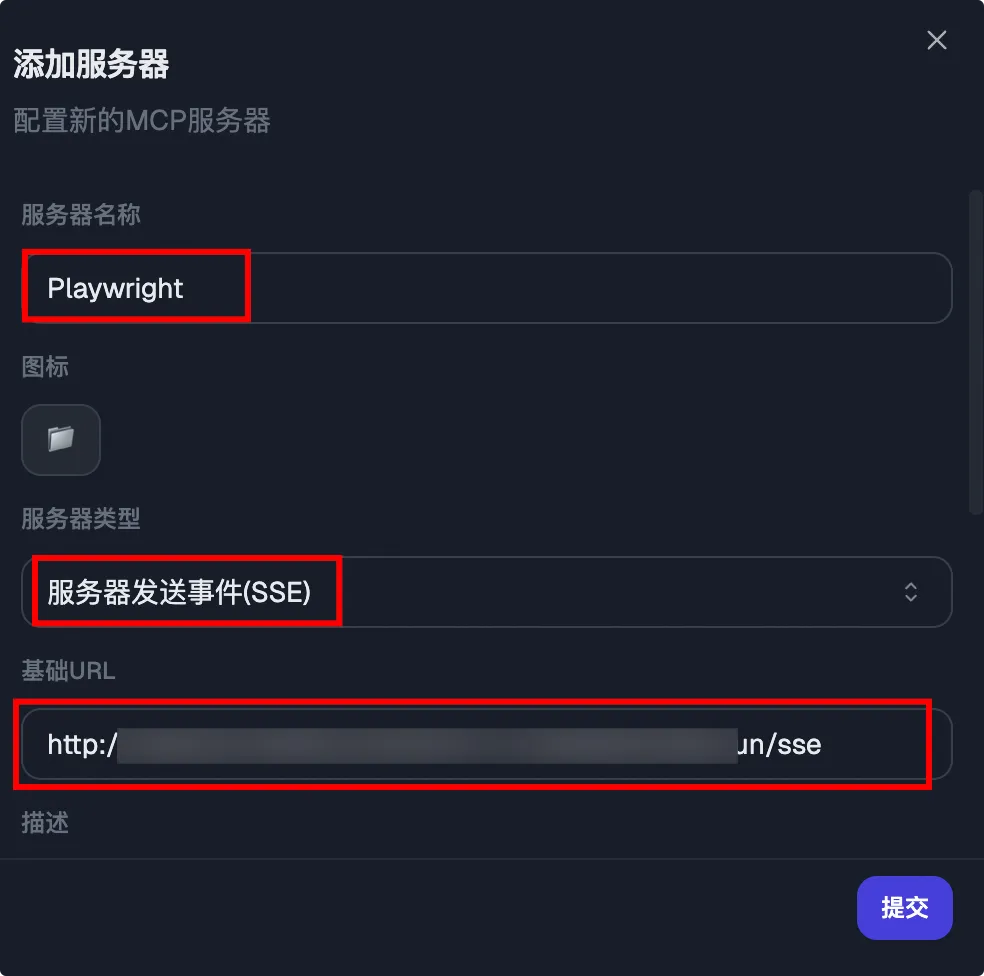
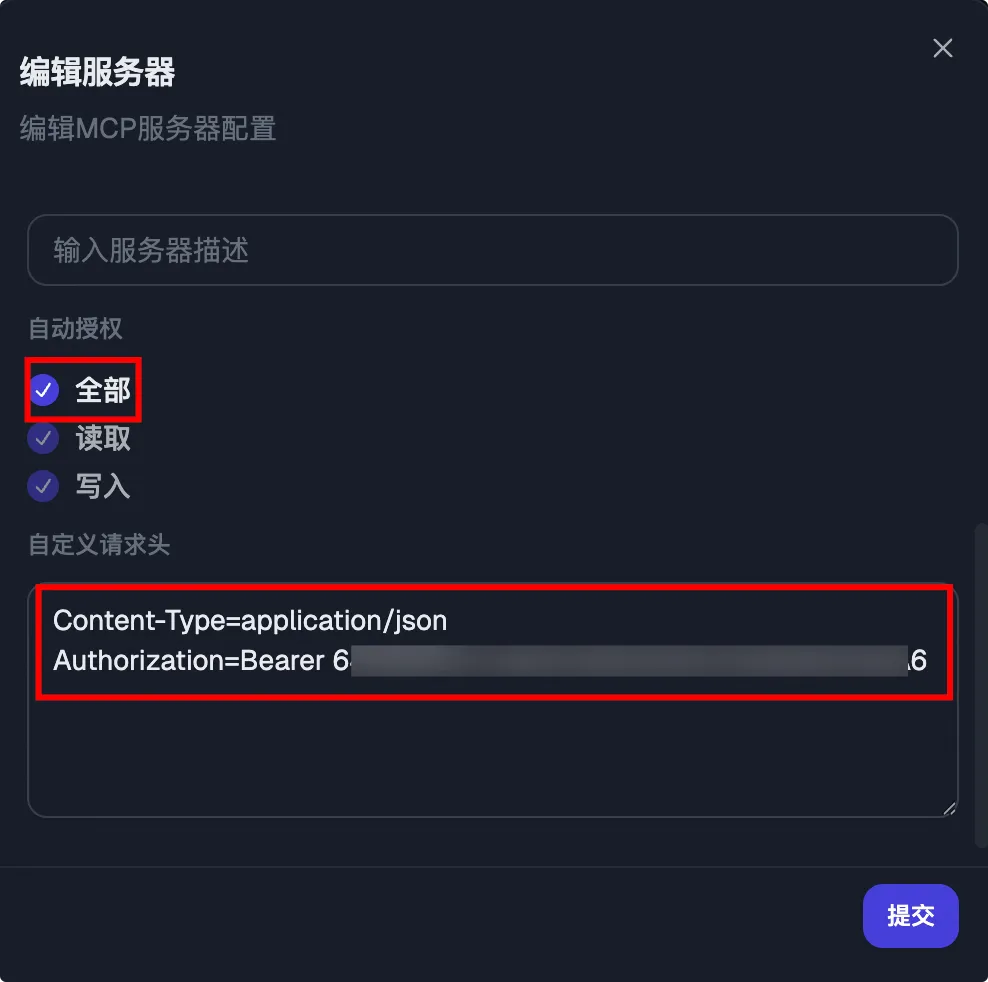
点击提交并开启该 MCP 服务后,可以看到我们提供的21个工具。
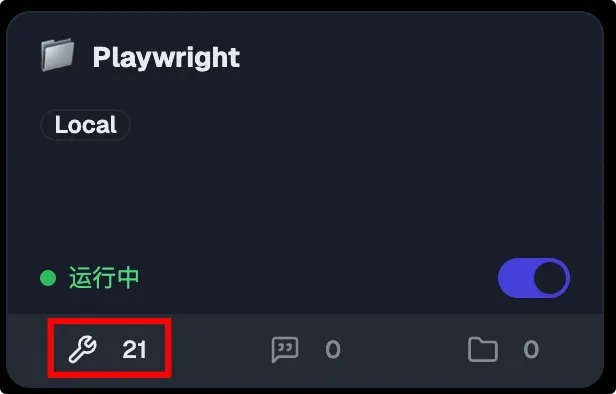
回到对话界面,开启 Playwright MCP 服务。
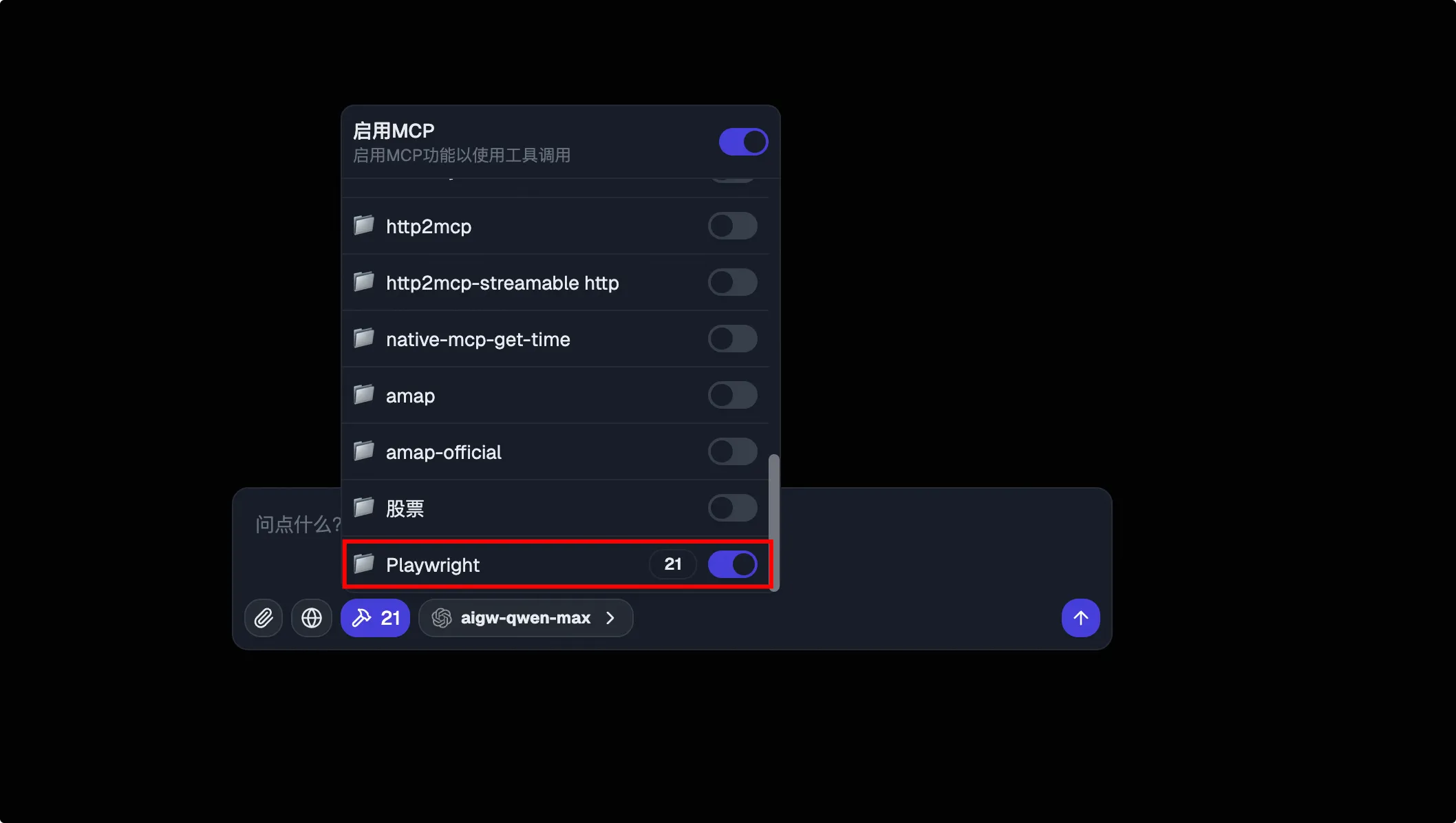
我们可以输入“使用浏览器,在 Bing 中搜索函数计算,列出前3条内容”。
此时,开始调用 Playwright MCP,对浏览器进行操作。

此时打开 NoVNC 客户端,可以看到界面中显示了浏览器,并访问了 Bing。
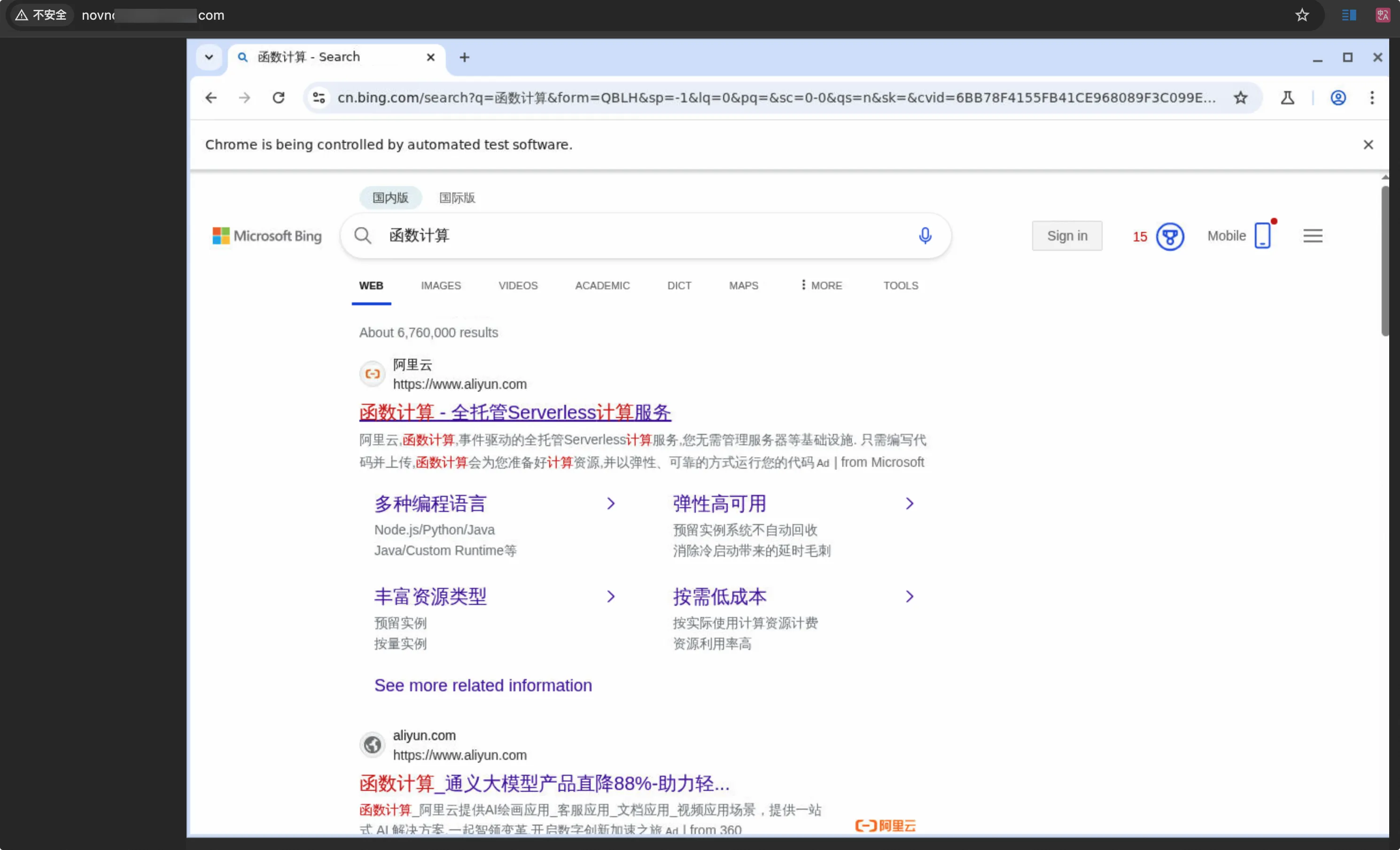
然后开始使用 browser_type 工具,也就是开始进行搜索。
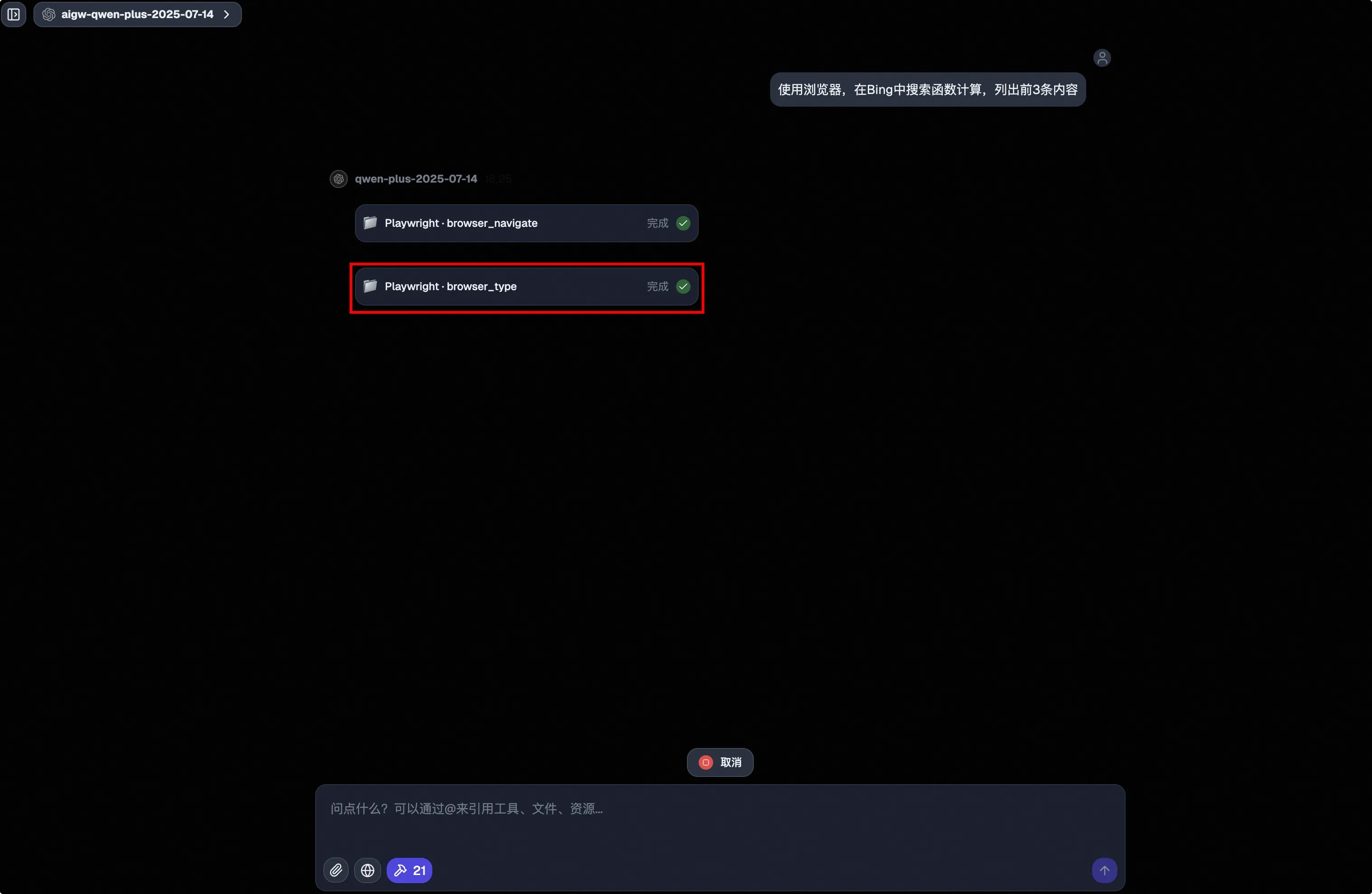
此时在 NoVNC 客户端可以看到在搜索框输入了函数计算,并进行了搜索。
最后显示出了结果。
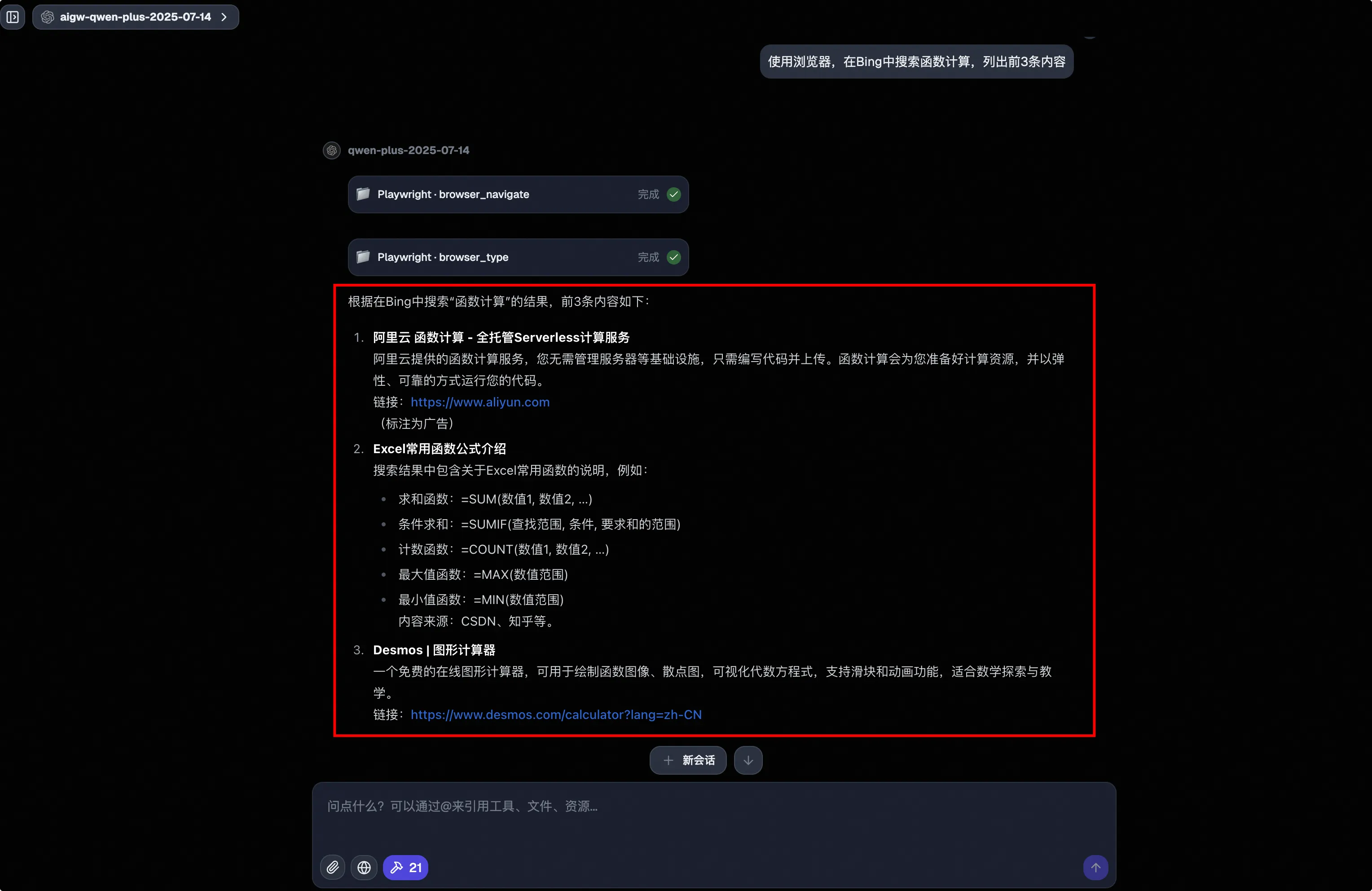
大家可以使用提供的其他工具玩出更多花样。
使用 Browser Use 框架稍微需要点编程能力。在熟悉的 Code IDE 中使用如下实例代码:
from browser_use import Agent, BrowserSession
from browser_use.llm import ChatDeepSeek
from browser_use.browser import BrowserProfile
from playwright.async_api import async_playwright
from dotenv import load_dotenv
import os
import asyncio
load_dotenv()
async def main():
browser_session_wss_url = "ws://[browserTool函数的连接地址]/ws/automation"
browser_session = BrowserSession(cdp_url=browser_session_wss_url, browser_profile=BrowserProfile(
headless=False,
user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36",
timeout= 3000000,
keep_alive=True,
))
# 需要修改DeepSeek的sk,如果您使用其他模型,请自行修改
llm = ChatDeepSeek(api_key="sk-your-deepseek-sk")
agent = Agent(
task="请访问 https://www.aliyun.com/product/list 并分析一下阿里云目前都提供了哪些产品",
llm=llm,
browser_session=browser_session,
use_vision=True
)
result = await agent.run()
print(result)
if __name__ == "__main__":
asyncio.run(main())

示例代码:
const puppeteer = require('puppeteer-core');
const browser = await puppeteer.connect({
browserWSEndpoint: 'ws://[browserTool函数的连接地址]/ws/automation/'
});
const page = await browser.newPage();
await page.goto('https://example.com');
await page.screenshot({ path: 'screenshot.png' });
await browser.close();
curl -X POST http://[browserTool函数的连接地址]/navigate \
-H "Content-Type: application/json" \
-d '{"url": "https://example.com", "wait_for":{"timeout": 3000}}'
● 截图:
curl-XPOSThttp://[browserTool函数的连接地址]/screenshot\
-H"Content-Type: application/json"\
-d'{"url": "https://example.com"}'\
--outputscreenshot.png
curl-XPOSThttp://[browserTool函数的连接地址]/pdf\
-H"Content-Type: application/json"\
-d'{"url": "https://example.com", "options": {"format": "A4"}}'\
--outputdocument.pdf
curl-XPOSThttp://[browserTool函数的连接地址]/content\
-H"Content-Type: application/json"\
-d'{"url": "https://example.com", "selector": "h1"}'
# 获取录制文件列表
curlhttp://localhost:3000/api/vnc/recordings
# 下载录制文件
curlhttp://localhost:3000/api/vnc/recordings/filename.fbs
# 删除录制文件
curl-XDELETEhttp://localhost:3000/api/vnc/recordings/filename.fbs
Context API:
# 创建 Context
curl-XPOSThttp://[browserTool函数的连接地址]/contexts\
-H"Content-Type: application/json"\
-d'{
"name":"test-session",
"browser":"chromium"
}'
# 使用 Context 进行操作
curl-XPOSThttp://[browserTool函数的连接地址]/contexts/navigate\
-H"Content-Type: application/json"\
-d'{
"context_id":"context-id",
"url":"https://example.com"
}'
更多内容关注 Serverless 微信公众号(ID:serverlessdevs),汇集 Serverless 技术最全内容,定期举办 Serverless 活动、直播,用户最佳实践。


 关注微信
关注微信