时间:2026-03-23 09:00
人气:
作者:admin
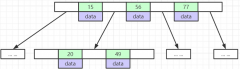
表空间由段(segment)、区(extent)、页(page)、行(row)组成,InnoDB存储引擎的逻辑存储结构大致如下图:

数据库表中的记录都是按行(row)进行存放的,每行记录根据不同的行格式,有不同的存储结构。
记录是按照行来存储的,但是数据库的读取并不以「行」为单位,否则一次读取(也就是一次 I/O 操作)只能处理一行数据,效率会非常低。
因此,InnoDB 的数据是按「页」为单位来读写的,也就是说,当需要读一条记录的时候,并不是将这个行记录从磁盘读出来,而是以页为单位,将其整体读入内存。
数据库的 I/O 操作的最小单位是页,InnoDB 数据页的默认大小是 16KB,意味着数据库每次读写都是以 16KB 为单位的,一次最少从磁盘中读取 16K 的内容到内存中,一次最少把内存中的 16K 内容刷新到磁盘中。

页的类型有很多,常见的有数据页、undo 日志页、溢出页等等。数据表中的行记录是用「数据页」来管理的
在 File Header 中有两个指针,分别指向上一个数据页和下一个数据页,连接起来的页相当于一个双向的链表,如下图所示:

数据页中的记录按照「主键」顺序组成单向链表,单向链表的特点就是插入、删除非常方便,但是检索效率不高,最差的情况下需要遍历链表上的所有节点才能完成检索。
因此,数据页中有一个页目录,起到记录的索引作用,就像我们书那样,针对书中内容的每个章节设立了一个目录,想看某个章节的时候,可以查看目录,快速找到对应的章节的页数,而数据页中的页目录就是为了能快速找到记录。
我们知道 InnoDB 存储引擎是用 B+ 树来组织数据的。
B+ 树中每一层都是通过双向链表连接起来的,如果是以页为单位来分配存储空间,那么链表中相邻的两个页之间的物理位置并不是连续的,可能离得非常远,那么磁盘查询时就会有大量的随机I/O,随机 I/O 是非常慢的。
解决这个问题也很简单,就是让链表中相邻的页的物理位置也相邻,这样就可以使用顺序 I/O 了,那么在范围查询(扫描叶子节点)的时候性能就会很高。
那具体怎么解决呢?
在表中数据量大的时候,为某个索引分配空间的时候就不再按照页为单位分配了,而是按照区(extent)为单位分配。每个区的大小为 1MB,对于 16KB 的页来说,连续的 64 个页会被划为一个区,这样就使得链表中相邻的页的物理位置也相邻,就能使用顺序 I/O 了。
表空间是由各个段(segment)组成的,段是由多个区(extent)组成的。段一般分为数据段、索引段和回滚段等。
总的来说,是因为超过2000W行后,B+树的层级会变高,导致IO次数增多
Mysql是根据数据页存储的,一个数据页默认是16KB。
当要查询一条记录时,InnoDB 是会把整个页的数据加载到 Buffer Pool 中,因为,通过索引只能定位到磁盘中的页,而不能定位到页中的一条记录。将页加载到 Buffer Pool 后,再通过页里的页目录去定位到某条具体的记录。
在B+树中非叶子节点是不存储数据的,只存储下一级的索引,所以在同样一个 16K 的页,非叶子节点里的每条数据都指向新的页,而新的页有两种可能
假设:
所以B+树中存储数据的总数 Total =$x^{z-1} *y$,也就是说总数会等于 x 的 z-1 次方 与 Y 的乘积。
非叶子节点容纳数据行数 —— x = ?
而页的中包含File Header (38 byte)、Page Header (56 Byte)、Infimum + Supermum(26 byte)、File Trailer(8byte), 再加上页目录,大概 1k 左右,假设这些信息就是 1K,那整个页的大小是 16K,剩下 15k 用于存数据,在索引页中主要记录的是主键与页号,主键假设是 Bigint (8 byte), 而页号也是固定的(4Byte), 那么索引页中的一条数据也就是 12byte。
那么一页中就能存储 x= $15*1024/12$≈1280 行数据
叶子结点容纳数据行数 —— y = ?
叶子节点和非叶子节点的结构是一样的,同理,能放数据的空间也是 15k。
假设一条行数据 1k 来算,那一页就能存下 15 条,Y = $15*1024/1000$ ≈15。
Total =$x^{z-1} *y$,已知 x=1280,y=15:
这个2.45kw,就是我们常说的单表建议最大行数2kw的由来。毕竟再加一层,数据就大得有点离谱了。三层数据页对应最多三次磁盘IO,也比较合理。
上面假设单行数据用了1kb,所以一个数据页能放个15行数据。
如果我单行数据用不了这么多,比如只用了250byte。那么单个数据页能放60行数据。
那同样是三层B+树,单表支持的行数就是 (1280 ^ (3-1)) * 60 ≈ 1个亿。
你看我一个亿的数据,其实也就三层B+树,在这个B+树里要查到某行数据,最多也是三次磁盘IO。所以并不慢。
比如实际当行的数据占用空间不是 1K , 而是 5K, 那么单个数据页最多只能放下 3 条数据。
还是按照 z = 3 的值来计算,那 Total = $1280 ^2*3$ = 4915200 (近 500w)
那么建议值就是不超过500w
我们都知道,现在MySQL的索引都是B+树,而有一种树,跟B+树很像,叫B树,也叫B-树。
它跟B+树最大的区别在于,B+树只在末级叶子结点处放数据表行数据,而B树则会在叶子和非叶子结点上都放。
于是,B树的结构就类似这样:

B树将行数据都存在非叶子节点上,假设每个数据页还是16kb,掐头去尾每页剩15kb,并且一条数据表行数据还是占1kb,就算不考虑各种页指针的情况下,也只能放个15条数据。数据页扇出明显变少了。
计算可承载的总行数的公式也变成了一个等比数列。15 + 15^2 +15^3 + ... + 15^z
其中z还是层数的意思。为了能放2kw左右的数据,需要z>=6。也就是树需要有6层,查一次要访问6个页。假设这6个页并不连续,为了查询其中一条数据,最坏情况需要进行6次磁盘IO。
而B+树同样情况下放2kw数据左右,查一次最多是3次磁盘IO。
磁盘IO越多则越慢,这两者在性能上差距略大。
为此,B+树比B树更适合成为MySQL的索引。
B+树叶子和非叶子结点的数据页都是16k,且数据结构一致,区别在于叶子节点放的是真实的行数据,而非叶子结点放的是主键和下一个页的地址。
B+树一般有两到三层,由于其高扇出,三层就能支持2kw以上的数据,且一次查询最多1~3次磁盘IO,性能也还行。
存储同样量级的数据,B树比B+树层级更高,因此磁盘IO也更多,所以B+树更适合成为MySQL索引。
索引结构不会影响单表最大行数,2kw也只是推荐值,超过了这个值可能会导致B+树层级更高,影响查询性能。
单表最大值还受主键大小和磁盘大小限制。
16KB页与B+树的平衡 :页大小限制了单页行数和指针数,B+树通过多阶平衡确保低树高。
2000万不是绝对 :若行小于1KB(如只存ID),上限可到5000万+;若行较大(如含大字段),可能500万就性能下降。
优化建议:
本文来自在线网站:seven的菜鸟成长之路,作者:seven,转载请注明原文链接:www.seven97.top

Hutool 的 `TimedCache` 到期会自动清理吗?

 关注微信
关注微信