时间:2025-09-28 15:49
人气:
作者:admin
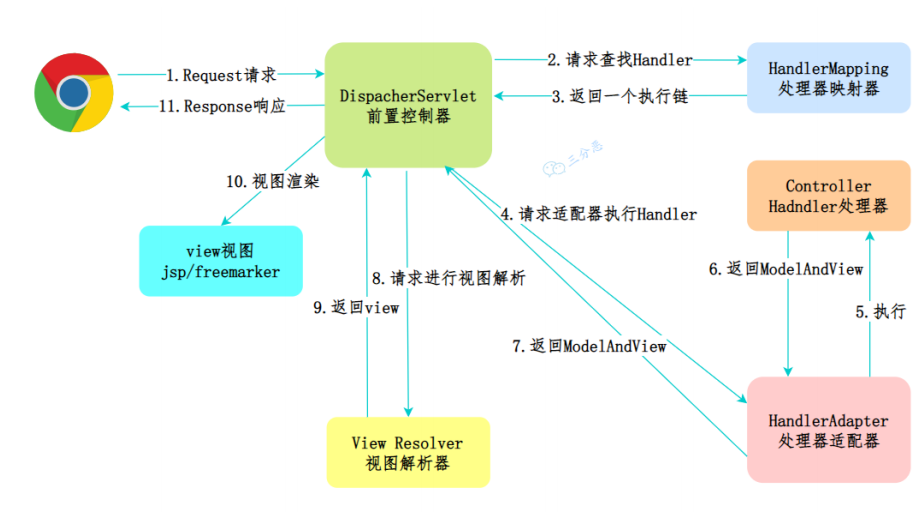
请求进入
浏览器发请求,首先到 DispatcherServlet(前端控制器)。
???? 相当于“总调度”。
找到处理器
DispatcherServlet 问 HandlerMapping:“这个请求该交给谁处理?”
HandlerMapping 返回对应的 Controller。
执行 Controller
DispatcherServlet 交给 HandlerAdapter 去执行 Controller 方法。
???? Controller 就是你写的 @GetMapping("/user") 这种方法。
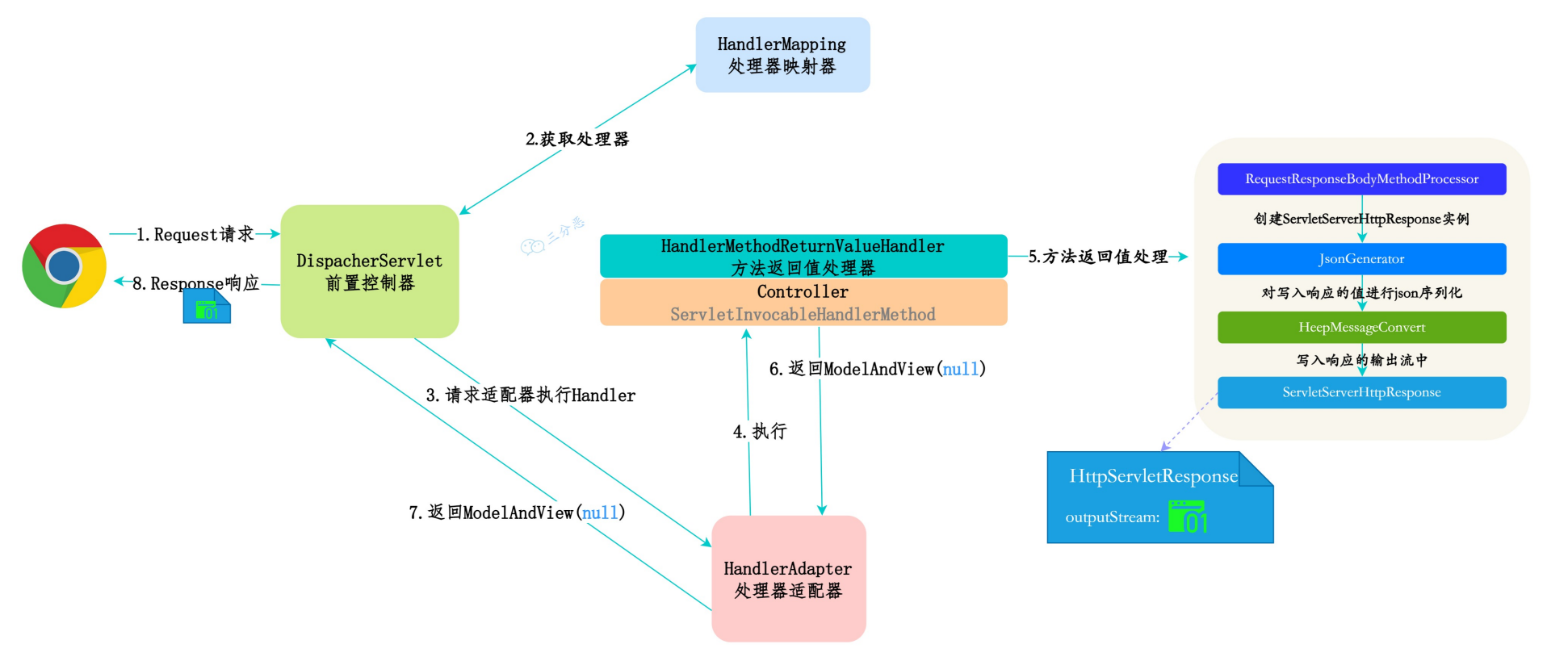
处理返回值
如果 Controller 方法上有 @ResponseBody,返回对象就要转成 JSON。
过程:
Spring 用 HttpMessageConverter(默认 Jackson)把对象序列化成 JSON。
写到响应的 OutputStream 里。
响应返回给浏览器
这时 JSON 已经写进了 HTTP 响应体,直接返回给客户端。
???? 如果方法返回 ModelAndView,才会走视图解析,这里返回的是 JSON,所以不需要。
spring-boot-starter-web,就能快速构建 Web 应用。传统Spring需要写一堆XML或配置,如web项目要自己配置DispatcherServlet、ViewResolver、消息转换器,数据库要自己配置dataSource等。那SpringBoot的最大特点就是这些常见配置不需要你写,自动帮你配好。
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}
1、 启动类上有一个@SpringBootApplication注解,这个注解里面包含@EnableAutoConfiguration。
2、SpringFactories 机制:Spring Boot 在自己的 jar 包里,放了一个文件:
META-INF/spring.factories。如果启用了自动配置,请把这些类也加载进来。
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\ org.springframework.boot.autoconfigure.web.servlet.WebMvcAutoConfiguration,\ org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration,\ ...
3、条件注解:比如DataSourceAutoConfiguration
@Configuration
@ConditionalOnClass(DataSource.class) // classpath 里有 DataSource 才生效
@ConditionalOnMissingBean(DataSource.class) // 容器里没有你自己定义的 DataSource 才生效
public class DataSourceAutoConfiguration {
// 自动帮你注册一个 DataSource bean
}
spring-boot-starter-jdbc → classpath 里就有 DataSource → 自动配置生效 ✅@Bean DataSource → Boot 就尊重你写的,不去覆盖 ❌@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}
application.yml / application.properties 里读配置。把数据库地址、端口号、日志级别等全都存好。@Component、@Service、@Repository、@Controller,Spring 都会扫描到。Spring Boot 还会根据依赖(比如 spring-boot-starter-web)自动帮你装好“常用机器”(Tomcat、Jackson、异常处理器等)。微服务是一种架构风格,代表着一种通过将应用程序拆分成小型、独立的功能模块的开发方式。每个模块(服务)实现独立的业务功能不限语言,服务之间通过轻量级的通信机制,如HTTP/REST或消息队列进行交互。微服务架构的核心思想是:解耦应用程序,提升灵活性和维护性。
微服务的优点:
缺点:分布式系统复杂性(服务器成本,开发人员成,运维成本增加)
引入Spring Cloud pom
<dependencyManagement>
<dependencies>
<!-- Spring Cloud 版本依赖(根据 Boot 版本来选) -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>2021.0.8</version> <!-- 举例,实际要看Boot版本 -->
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- Spring Cloud Alibaba 版本依赖(Nacos, Sentinel, Seata 等) -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2021.0.5.0</version> <!-- 要和上面保持兼容 -->
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
假设现在有个小demo,有两个功能(下单、库存),这时候下单服务是通过用HTTP的方式来调用库存服务的接口。假设这个库存服务进行了集群,就会有很多的地址和端口,如果都需要自己去管理的话会非常麻烦。这时候就可以用nacos来帮我们解决这个问题。
(1)安装nacos服务:https://nacos.io/download/nacos-server/?spm=5238cd80.c984973.0.0.6be14023Dk5qSI
(2)打开安装好的文件夹conf,application.properties文件,因为nacos里面有很多数据要持久化,所以我们要连接数据库,根据原本的配置去创建一个'nacos'数据库(记得数据库名字要和配置里面的一致)。把安装包的mysql-schema.sql文件在新建的这个数据库运行一下,就会产生很多个数据表。
(3)打开安装包的bin,里面的startup.cmd文件(因为默认是集群方式启动),把'cluster'改为'standalone'(set MODE = 'standalone')。双击启动即可,端口是8848。接下来可以通过localhost:8848/nacos启动,就可以打开nacos的控制面板。
(4)引入具体的Spring Cloud组件
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
(5)在两个服务的启动类上加入@EnableDiscoveryClient, 表示当前应用启用了nacos的服务。
(6)在两个服务的application.yml的文件中修改配置。
spring: application: name: order-server cloud: nacos: discovery: server:addr: 127.0.0.1:8848
(7)启动项目,在nacos控制面板就可以看到两个服务。
(8)服务发现集成Spring Cloud Loadbalancer组件(放在需要远程调用的消费者端order)。然后再OrderApplication中的public RestTemplate上加一个@LoadBalanced注解。然后在OrderController就可以通过服务名访问了。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>
//原来是写死的 http://localhost:8082/xxx,现在换成 服务名调用: @RestController @RequestMapping("/order") public class OrderController { @Autowired private RestTemplate restTemplate; @RequestMapping("/add") public String add() { System.out.println("下单成功!"); // 这里直接用服务名 "stock-service" 替代固定的IP和端口 String msg = restTemplate.getForObject("http://stock-service/stock/reduce", String.class); return "Hello World " + msg; } }
(9)现在我们尝试调用下单接口,这时也会扣减库存,说明通过nacos管理服务的方式正确了。如果我们配置的是集群,那么这个服务在nocos面板中会显示集群数为10、实例数为10、健康数为10(全是健康的情况下),如果有五台down掉了,那么nacos不会去调用那五个服务,而是选择健康的实例。
(1)集成OpenFeign
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
(2)在启动类中加@EnableFeignClients
(3)新建一个包feignService,StockFeignService.java,用于声明要调用的远程接口:
@FeignClient(name = "stock-service", path = "/stock") public interface StockFeignService { // 调用库存服务的 /stock/reduct 接口 @RequestMapping("/reduct") String reduct(); }
这样,就等于给 stock-service 定义了一个“本地接口代理”,底层由 Feign + Ribbon(或 LoadBalancer) 完成服务发现和调用。
(4)在Controller中调用
@RestController @RequestMapping("/order") public class OrderController { @Autowired private StockFeignService stockFeignService;
@Autowired
StockFeignService stockFeighService;
9、@RequestMapping("/add") public String add() { System.out.println("下单成功!"); String msg = stockFeignService.reduct(); // 调用远程库存服务 return "Hello World " + msg; } }
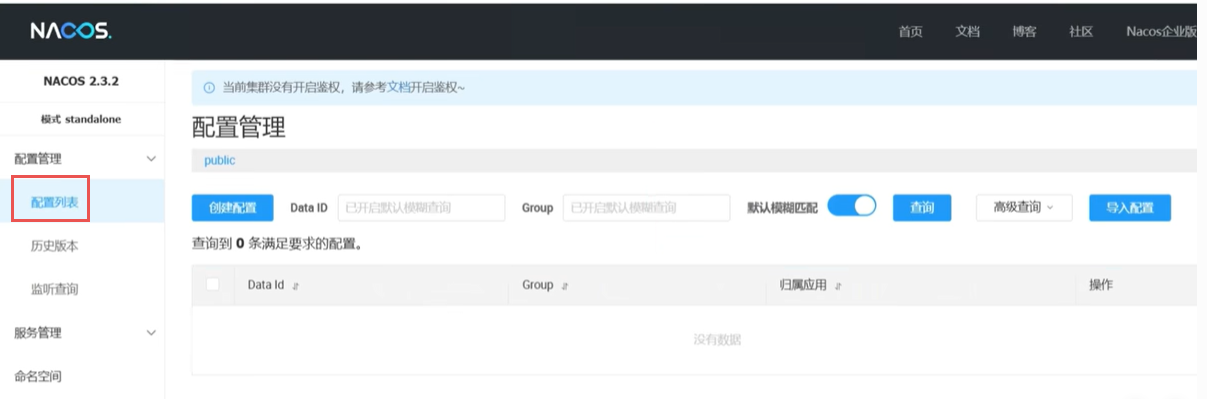
在这里可以创建一个通用的配置中心,新建一个配置。
//在nacos中配一个author: yi spring: application: name: order-server cloud: nacos: discovery: server-addr: 127.0.0.1:8848 config: server-addr: 127.0.0.1:8848 config: import: - nacos: order-server.yaml //这样就可以在OrderController中注入就可以用了
//加入@RefreshScope注解可以实时更新
@RefreshScope
public class OrderController{
@Value("${author}")
String author;
}
没有网关时,客户端需要直接访问各个服务的端口。比如:
订单服务(order-service)在 8081 端口,访问路径是 http://localhost:8081/order/add
库存服务(stock-service)在 8082 端口,访问路径是 http://localhost:8082/stock/reduct
这样客户端就需要知道 每个服务的地址和端口,而且一旦端口变更,客户端也要跟着改,非常不方便。
客户端负担重:需要知道每个微服务的端口和路径,无法统一入口。
安全性不足:没有统一的权限校验和鉴权机制,只能在每个服务单独实现。
无法集中治理:像限流、熔断、灰度发布等能力没办法统一做。
对外暴露风险大:每个服务都要直接暴露在公网,增加了安全风险。
有网关:客户端只需要调用一个统一入口,比如 http://api.xxx.com/order/add,网关负责路由到对应服务,还能顺带做鉴权、限流。
做法:
(1)网关是个单独的服务,我们要新建一个模块。
(2)引入pom
<dependencies>
<!-- Spring Boot WebFlux(Gateway 基于 WebFlux,而不是 Spring MVC) -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<!-- Spring Cloud Gateway 核心依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<!-- Nacos 服务发现(或其他注册中心,比如 Eureka、Consul,根据你的实际情况选择) -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<!-- Spring Boot Actuator(可选,但通常推荐,用于健康检查与监控) -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
</dependencies>
(3)在新建的这个模块的配置文件中配置Spring Cloud Gateway路由。如果请求的url中有/order/*的话,就把路由分发到以下那个order-server服务。
# 还需要注册中心、配置中心 spring: application: name: gateway cloud: gateway: #路由规则 routes: - id: order route # 路由的唯一标识,路由到order url: lb.//order-server # 需要转发的地址 # 断言规则 用于路由规则的匹配 predictions: - Path = /order/**
spring: application: name: order-server cloud: nacos: discovery: server-addr: 127.0.0.1:8848 config: server-addr: 127.0.0.1:8848 config: import: - optional: nacos: gateway.yaml # 表示可有可无可选的
注意:去除spring-boot-starter-web,不能同时和gateway出现。
流程:用户请求首先经过 Nginx 作为统一入口,Nginx 将流量转发到 Spring Cloud Gateway。网关负责 请求路由与负载均衡,并根据服务发现机制,从 Nacos 注册中心 获取最新的微服务地址。随后,网关将请求分发到具体的 微服务实例(如订单服务、库存服务),实现服务的动态调用。同时,微服务在启动时会向 Nacos 注册自身信息,Nacos 还能推送配置变化,从而保证整个系统在高并发下依然具备可扩展性与可管理性。
在单体应用里,@Transactional 就像一把锁,可以保证这段业务里的数据库操作要么都成功,要么都回滚。但在微服务里,每个服务有自己的数据库,比如下单服务、库存服务、账户服务各管一摊,@Transactional 只能管好自己那一摊,跨服务就管不了了。这样一来,下单成功了但库存没扣、余额没减的情况就可能发生,所以要用 Seata 这样的分布式事务工具来帮忙“统一指挥”,保证多个服务的数据一致。
前置:在订单服务和库存服务的配置文件中进行补充数据库和mybatis的配置。
Seata 基于 全局事务协调器 (TC) + 事务管理器 (TM) + 资源管理器 (RM) 实现。
TM(Transaction Manager):发起并结束全局事务。
RM(Resource Manager):管理分支事务(数据库操作),并向 TC 注册分支事务。
TC(Transaction Coordinator):全局事务协调器,负责全局事务的提交或回滚。
一句话总结:
???? TM 负责开启/提交/回滚全局事务,TC 负责全局事务的调度与协调,RM 负责具体数据库操作并上报给 TC。(TM 发起,TC 指挥,RM 执行。)
在订单服务、库存服务等需要分布式事务的模块中引入:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
</dependency>
在 application.yml 中配置:
spring:
cloud:
alibaba:
seata:
tx-service-group: my_test_tx_group
然后在 resources 目录下新建 file.conf 和 registry.conf,配置 Seata 注册中心(可以是 Nacos、Eureka 或 file 模式)。
@GlobalTransactional@RestController @RequestMapping("/order") public class OrderController { @Autowired private OrderService orderService; @RequestMapping("/add") public String add() { orderService.createOrder(); return "下单成功!"; } } @Service public class OrderService { @Autowired private OrderMapper orderMapper; @Autowired private StockFeignService stockFeignService; @GlobalTransactional(name = "order-create-tx", rollbackFor = Exception.class) public void createOrder() { // 1. 新增订单 Order order = new Order(); order.setProductId(9); order.setStatus(0); order.setTotalAmount(100); orderMapper.insert(order); // 2. 调用库存服务扣减库存 stockFeignService.reduct(order.getProductId()); // 3. 模拟异常 int a = 1 / 0; } }
库存服务:
@Service public class StockService { @Autowired private StockMapper stockMapper; public void reduct(int productId) { stockMapper.reduce(productId); System.out.println("扣减库存成功"); } }
如果程序 正常执行,订单库写入成功,库存库扣减成功,全局事务提交;
如果程序 出现异常(比如 int a = 1/0;),Seata 会自动通知各个分支事务回滚,订单库和库存库的数据都会恢复到原始状态,实现强一致性。订单服务在 orderMapper.insert(order) 里写入订单数据。库存服务在 stockFeignService.reduct(productId) 里扣减库存。执行到 int a = 1 / 0 抛异常。Seata 的 全局事务协调器 (TC) 捕捉到异常,通知各个参与的分支事务(订单库 + 库存库)执行 回滚。
当库存服务的方法执行时,它其实是运行在Seate的RM管控下的,库存服务一启动,就会把它的数据源代理成Seata的DataSourceProxy。这样每一次数据库操作都会被拦截,并且记录到一个”回滚日志表“(undolog)。在执行时,库存服务会向全局事务协调器(TC)报告:我现在是订单事务里的一个分支事务,我做了哪些 SQL 改动,原始值是什么,新值是什么。
当订单服务抛出异常时,TM(事务管理器)会告诉TC:全局事务失败,要回滚。TC通知所有已经注册过的分支事务(包括订单库和库存库)”你们刚刚执行的SQL全都撤销“。RM(资源管理器)根据之前记录的undolog,把数据恢复到更新前的样子。
相比于本地事务的 @Transactional,Seata 的 @GlobalTransactional 可以让分布式场景下的多个服务 像在一个数据库里操作一样,从而保证数据一致性。它非常适合应用在 下单-库存-账户 这类 跨服务、跨库的核心业务链路。
在分布式微服务架构中,高并发是常见场景。如果没有流控措施,突发流量会导致某个服务被打挂,从而引起系统雪崩。
Sentinel 就是阿里开源的流量治理框架,支持 流量控制、熔断降级、系统保护等功能。
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
//在 application.yml 中配置 Sentinel 控制台地址(先启动 sentinel-dashboard): spring: application: name: order-server cloud: nacos: discovery: server-addr: 127.0.0.1:8848 sentinel: transport: dashboard: localhost:8080 # Sentinel 控制台 port: 8719 # 与控制台通信端口
@RestController @RequestMapping("/order") public class OrderController { @GetMapping("/add") @SentinelResource(value = "addOrder", blockHandler = "handleBlock") public String add() { return "下单成功!"; } // 限流或熔断时执行 public String handleBlock(BlockException ex) { return "系统繁忙,请稍后再试~"; } }
//这样,当 QPS 超过 Sentinel 配置的阈值时,就会自动调用handleBlock方法,避免系统崩溃。
Queries Per Second,每秒请求数。
QPS = 每秒钟系统能处理的请求数,比如你的接口一秒钟能正常处理 100 次调用。
如果突然来了 500 次调用,系统可能直接挂掉(CPU 爆满、数据库崩溃)。
Sentinel 就像“限流器”,当检测到 请求数超过阈值,会触发
handleBlock(),给用户返回友好提示,而不是让系统直接崩溃。
在实际业务中,比如 下单扣减库存,如果用户量突然激增,直接写库会给数据库造成很大压力。
解决方案就是引入 消息队列(MQ),把请求写到队列里,由消费者异步慢慢处理,起到 削峰填谷的作用。
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-spring-boot-starter</artifactId>
<version>2.2.2</version>
</dependency>
spring: application: name: order-server cloud: nacos: discovery: server-addr: 127.0.0.1:8848 rocketmq: name-server: 127.0.0.1:9876 # RocketMQ 服务地址 producer: group: order-producer-group
@RestController @RequestMapping("/order") public class OrderController { @Autowired private RocketMQTemplate rocketMQTemplate; @GetMapping("/add") public String add() { // 发送下单消息到库存服务的 topic rocketMQTemplate.convertAndSend("order-topic", "下单一笔"); return "下单请求已提交!"; } }
@Service @RocketMQMessageListener(topic = "order-topic", consumerGroup = "stock-consumer-group") public class StockConsumer implements RocketMQListener<String> { @Override public void onMessage(String message) { System.out.println("收到消息:" + message); // 扣减库存逻辑 } }
这样,订单服务只负责把消息写入 MQ,真正的库存扣减逻辑由消费者异步执行,大大提升系统抗压能力。
在微服务架构下,一个请求可能会经过 网关 → 订单服务 → 库存服务 → 支付服务 等多个服务,如果某个环节出问题(慢、报错),很难排查到底是哪一段出了问题。
???? 这时候就需要用 SkyWalking 这样的分布式链路追踪工具。
在每个服务中,SkyWalking 通过 探针 Agent 自动拦截请求调用链。
每个请求会生成一个 TraceId,贯穿整个调用链。
系统会把请求耗时、接口调用情况、异常信息都上报给 SkyWalking OAP Server。
最终你可以在 SkyWalking UI 上看到一条完整的调用链路,比如:
网关 → 订单服务 → 库存服务 → 数据库,每一环的耗时、错误一目了然。
在你的 订单服务、库存服务 启动命令中,加上 SkyWalking Agent:
java -javaagent:/path/to/skywalking-agent/skywalking-agent.jar \ -Dskywalking.agent.service_name=order-service \ -Dskywalking.collector.backend_service=127.0.0.1:11800 \ -jar order-service.jar
-javaagent:指定 SkyWalking 的探针 jar 包。
service_name:服务的名称(区分不同微服务)。
backend_service:SkyWalking OAP 的地址(默认 11800 端口)。
假设用户下单:
请求先到 Gateway,Gateway 转发到 订单服务。
订单服务内部调用 库存服务,库存服务再操作数据库。
SkyWalking 会自动收集这些调用链路,生成 Trace。
在 UI 上能看到一条完整链路:
Gateway(20ms) → OrderService(50ms) → StockService(80ms) → MySQL(30ms)
如果某个环节出错,会显示红色告警。
可观测性强:能精确定位系统瓶颈。
零侵入性:不需要改业务代码,只需挂载探针。
适合排查分布式问题:在复杂微服务环境下快速定位错误环节。
参考:
https://www.b ilibili.com/video/BV1apr6YyEGg?spm_id_from=333.788.player.switch&vd_source=99ec55b57f4eeedd9ed62c43e87cb6ff&p=3
上一篇:JUC: 线程锁

Hutool 的 `TimedCache` 到期会自动清理吗?

 关注微信
关注微信