时间:2026-01-21 19:35
人气:
作者:admin
如果你真正做过大模型微调,大概率经历过这些瞬间:
很多工程师第一次做 RLHF,都会天真地以为:
reward 提升 = 模型变好
直到 PPO 狠狠给你上了一课。
现实是:
大模型不是不能优化,而是不能被“猛优化”。
这也是为什么,在几乎所有成功落地的大模型对齐系统中,PPO 最终都成了“兜底方案”。
不是因为它最先进,而是因为——
它最不容易把模型训崩。
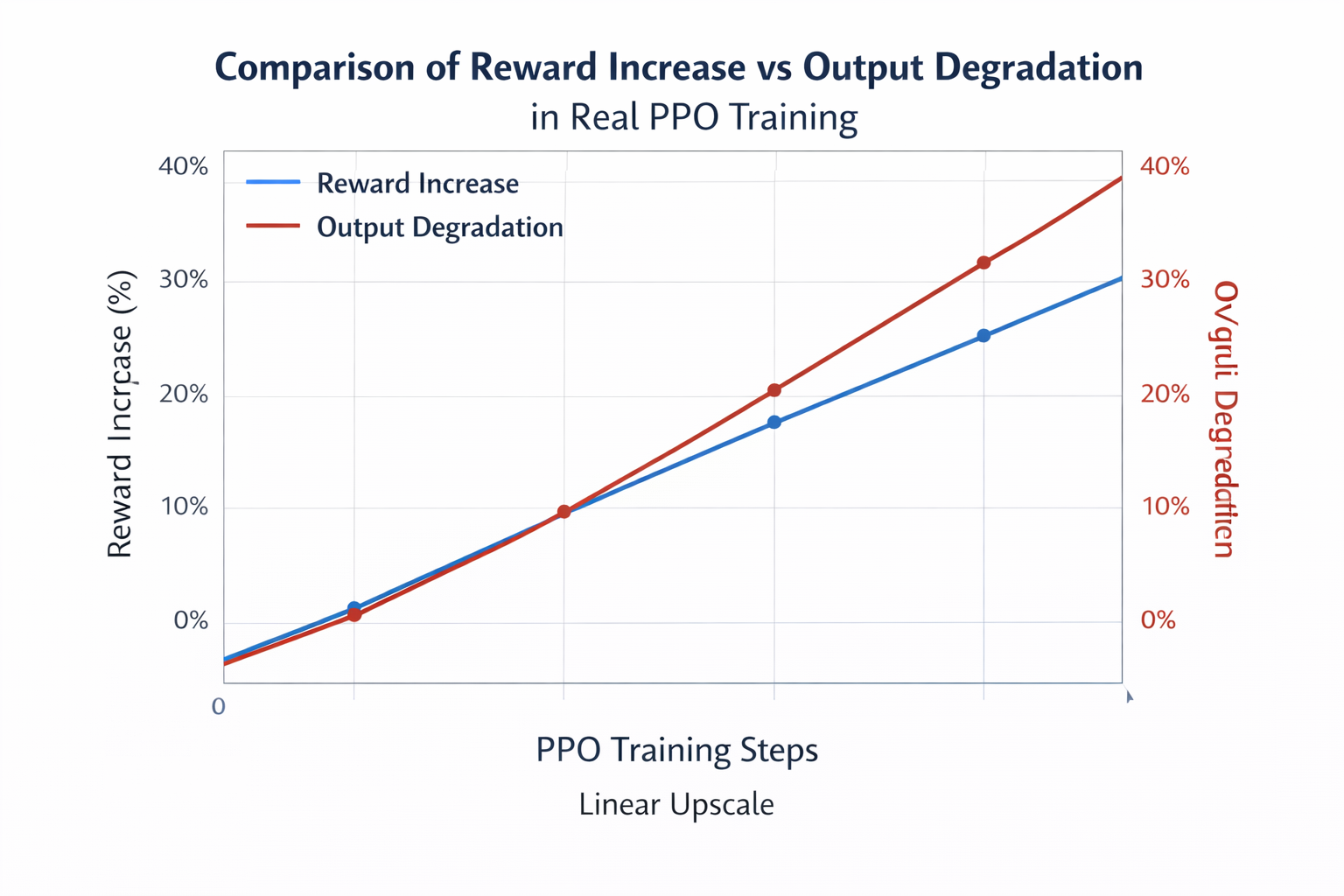
先说一个反直觉的事实:
在大模型上,reward 提升越快,越危险。
原因很简单。
语言模型的策略空间太大了。
在强化学习的数学世界里,策略梯度听起来很美:
最大化期望回报
但在真实工程里,它等价于:
于是你会看到:
问题不在 reward,而在“变化幅度没人管”。
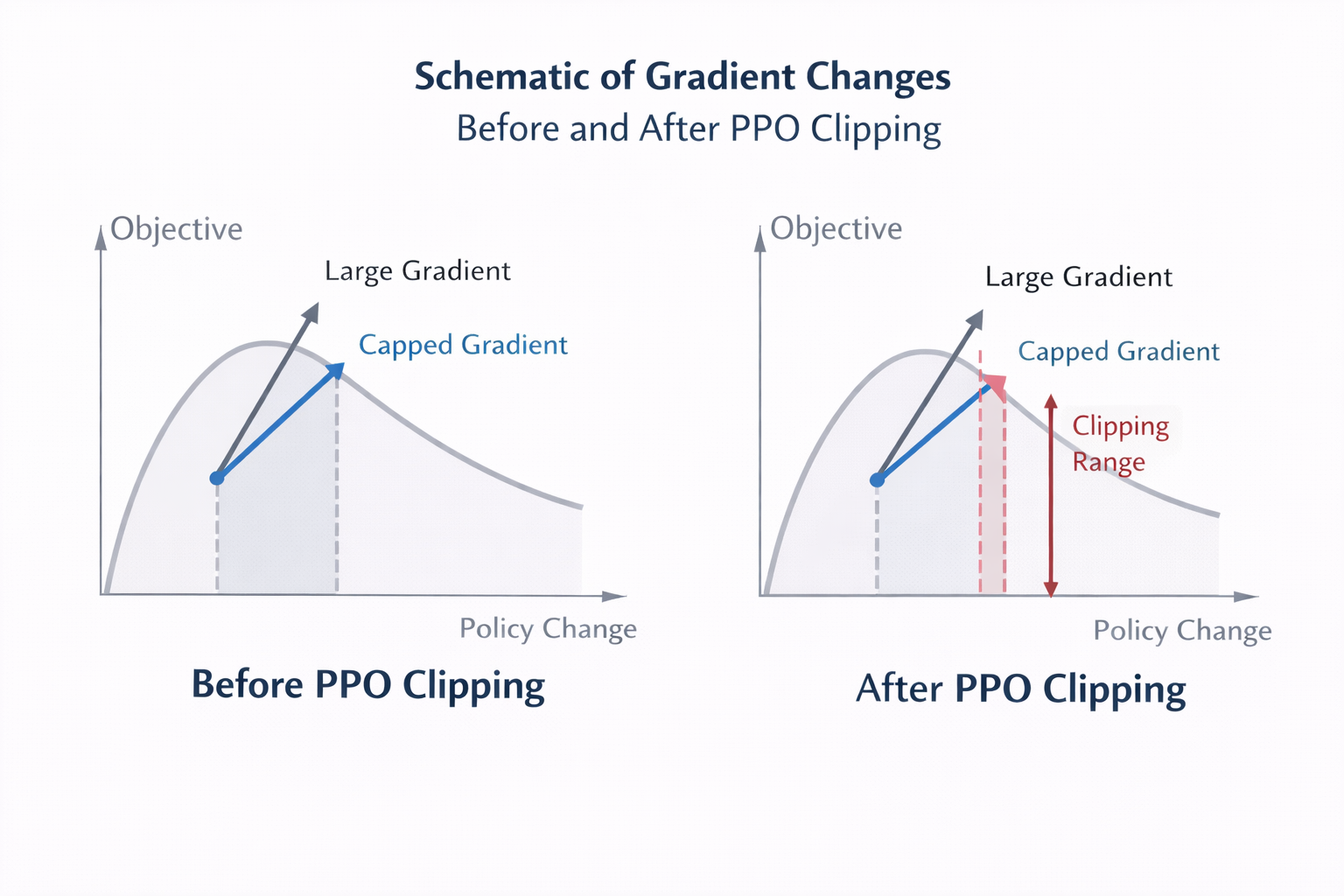
理解 PPO,只需要记住一句话:
PPO 干的不是“怎么多学一点”,而是“每次只学一点点”。
PPO 最核心的设计,是一个极其工程化的妥协:
数学上,它通过一个 clipping 机制实现。
直觉版解释是:
这就是为什么 PPO 在大模型里异常稳定。
如果你只记 PPO 的一个工程经验,那就是这条:
不加 KL 的 PPO,迟早翻车。
KL 项的本质是:
在 RLHF 场景中,KL 的作用比 reward 本身还重要。
KL 太小,模型会:
KL 太大,模型会:
真正成熟的系统,都会:
下面这部分,是工程师最该看的地方。
一轮真正可落地的 PPO 微调,长这样。
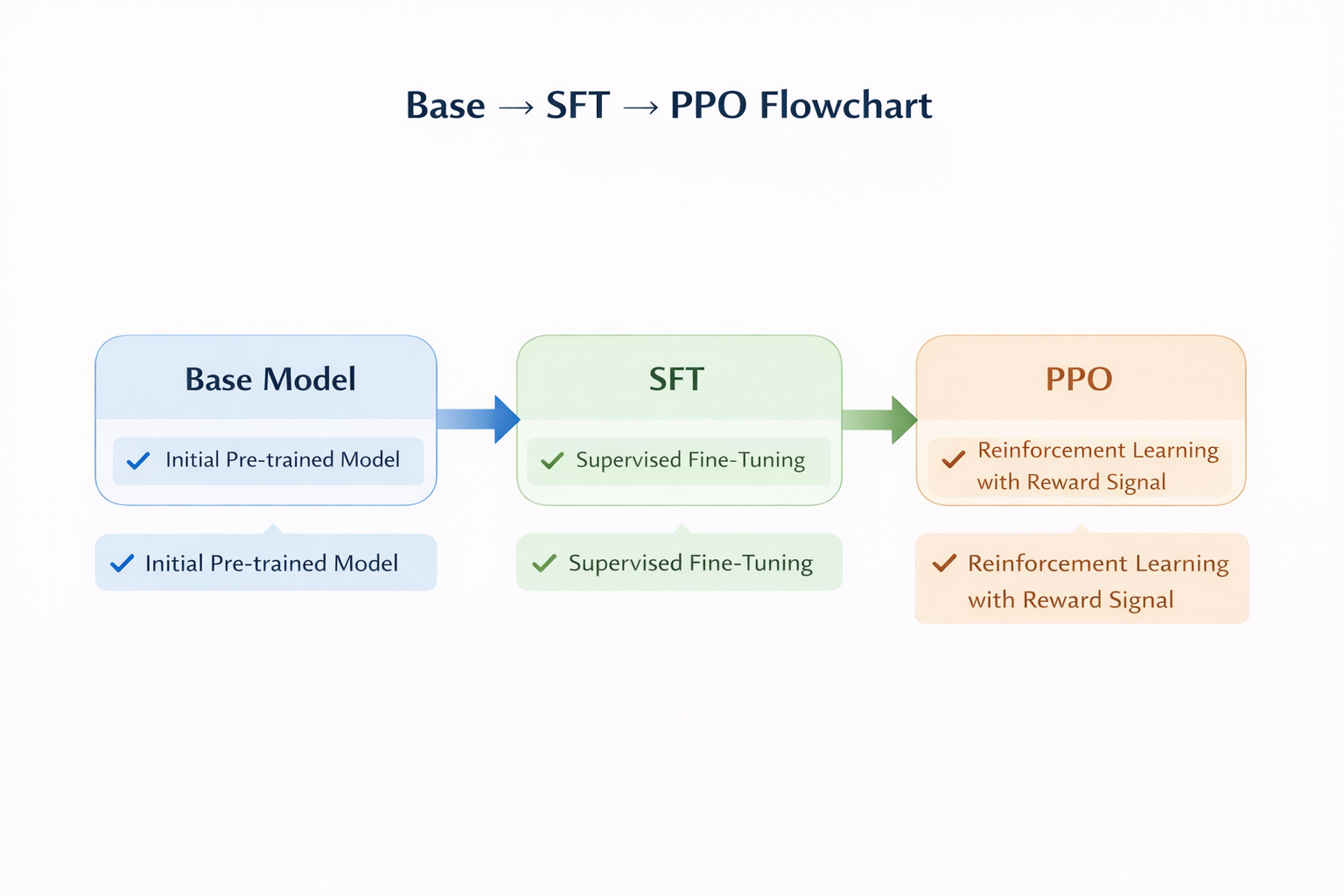
这是 90% 新手会犯的错误。
PPO 从来不是用来“教模型说话”的,而是:
没有 SFT 打底,PPO 只会放大噪声。
一个现实结论:
一个稳定的 6B Reward Model
比一个不稳定的 70B 好得多
Reward Model 的一致性,远比“聪不聪明”重要。
工程建议是:
高度简化后,PPO 在大模型里的核心逻辑是:
responses = policy.generate(prompts)
reward = reward_model(responses)
kl_penalty = kl(policy, ref_policy)
total_reward = reward - beta * kl_penalty
advantage = total_reward - value_prediction
update_policy_with_ppo(advantage)
真正影响稳定性的,从来不是公式,而是:
如果你不想一开始就陷入 PPO 工程细节地狱,LLaMA-Factory online 已经把 PPO + KL + Reward Model 的完整链路跑通,非常适合作为第一版对齐实验环境。
一些非常值钱的经验:
正确顺序是:
如果你只看 reward,那你基本已经走偏了。
靠谱的评估方式一定包括:
你要问的不是:
reward 涨了吗?
而是:
模型是不是还像个正常人?

会,但不是现在。
DPO、IPO、各种“无 RL 对齐”方法正在快速发展,但在真实工程里:
它不是最优雅的算法,
但是最像工程方案的算法。
如果你的目标是 稳住模型 + 快速验证对齐策略,用 LLaMA-Factory online 跑通 PPO 全流程,再逐步精细化,是目前性价比极高的一条路径。





 关注微信
关注微信